Kiểm định Bootstrap trong mô hình SEM bằng AMOS: Cơ sở lý thuyết và cách thực hiện chuẩn
Kiểm định Bootstrap trong SEM bằng AMOS là kỹ thuật lấy mẫu lại phi tham số giúp kiểm định độ ổn định của các ước lượng khi dữ liệu không phân phối chuẩn hoặc cỡ mẫu hạn chế. Bài viết này trình bày cơ sở lý thuyết, quy trình thực hiện Bootstrap trong AMOS và cách diễn giải kết quả đúng chuẩn luận văn, đồng thời làm rõ và bác bỏ cách hiểu sai về công thức CR thường gặp trong các nghiên cứu SEM.
1. Kiểm định Bootstrap trong SEM là gì?
Trong mô hình cấu trúc tuyến tính (Structural Equation Modeling – SEM), phương pháp ước lượng phổ biến nhất là Maximum Likelihood (ML). Tuy nhiên, ML giả định dữ liệu tuân theo phân phối chuẩn, trong khi dữ liệu nghiên cứu thực tế (đặc biệt là dữ liệu khảo sát hành vi, xã hội) thường vi phạm giả định này.
Bootstrap được đề xuất như một giải pháp phi tham số, giúp:
-
Đánh giá độ ổn định của ước lượng
-
Kiểm tra độ chệch (Bias) của các tham số
-
Tăng độ tin cậy của kết luận giả thuyết
Theo Efron & Tibshirani (1993) và Hair et al. (2019), Bootstrap là phương pháp lấy mẫu lại (resampling) từ tập dữ liệu gốc để xây dựng phân phối thực nghiệm của các ước lượng.
2. Quy trình kiểm định Bootstrap trong AMOS
Bước 1: Chạy mô hình SEM bằng phương pháp ML (Maximum Likelihood)
Trước khi thực hiện kiểm định Bootstrap, mô hình SEM cần được ước lượng bằng ML để đánh giá độ phù hợp mô hình và ý nghĩa các giả thuyết nghiên cứu.
Để nắm rõ quy trình phân tích SEM trong AMOS, cách kiểm định giả thuyết và đọc hệ số chuẩn hóa, bạn có thể tham khảo bài viết: Phân tích SEM trong AMOS .
Bước 2: Thiết lập Bootstrap trong AMOS
Sau khi mô hình SEM được ước lượng bằng ML và đạt độ phù hợp chấp nhận được, tiến hành thiết lập Bootstrap để đánh giá độ ổn định của các ước lượng.
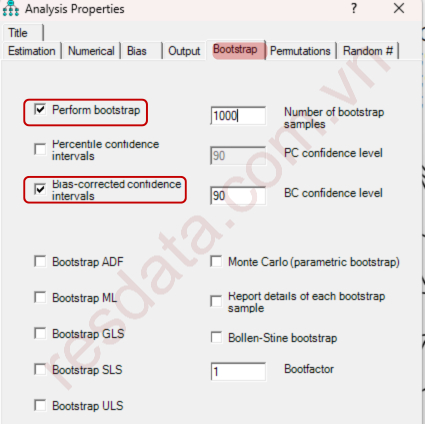
Trong AMOS, chọn Analysis Properties → Bootstrap.
.jpg)
Tích chọn Perform bootstrap và thiết lập số mẫu Bootstrap (thường từ 1.000–5.000 mẫu). Đồng thời, nên chọn Bias-corrected confidence intervals để tăng độ tin cậy khi dữ liệu không phân phối chuẩn
Bước 3: Chạy Bootstrap và xuất kết quả
Sau khi hoàn tất thiết lập Bootstrap trong AMOS, tiến hành chạy mô hình bằng cách nhấn Calculate Estimates. AMOS sẽ thực hiện quá trình lấy mẫu lặp lại có thay thế với số lần lặp đã thiết lập (B = 1.000 mẫu).
.jpg)
Khi quá trình chạy hoàn tất, kết quả Bootstrap được xuất trong phần View Text, bao gồm:
-
Bảng Bootstrap Estimates cho các hệ số đường dẫn
-
Thông tin Mean, Bias, SE-Bias
-
Khoảng tin cậy Bootstrap (Bootstrap Confidence Intervals)
Các kết quả này được sử dụng để đánh giá mức độ ổn định và độ tin cậy của các ước lượng trong mô hình SEM ban đầu.
Bước 4: Phân tích và đọc kết quả Bootstrap
Sau khi chạy Bootstrap trong AMOS, bạn cần truy xuất đúng bảng kết quả liên quan đến Bootstrap, thay vì sử dụng các bảng kết quả mặc định của phương pháp ML. Trong cửa sổ View Text Output của AMOS, lựa chọn mục Standardized Regression Weights để xem các hệ số hồi quy chuẩn hóa của mô hình. Khi Bootstrap được kích hoạt, AMOS đồng thời cung cấp Bootstrap standard errors và Bias-corrected confidence intervals tương ứng cho các hệ số này, cho phép đánh giá độ ổn định và ý nghĩa thống kê của các mối quan hệ trong mô hình.
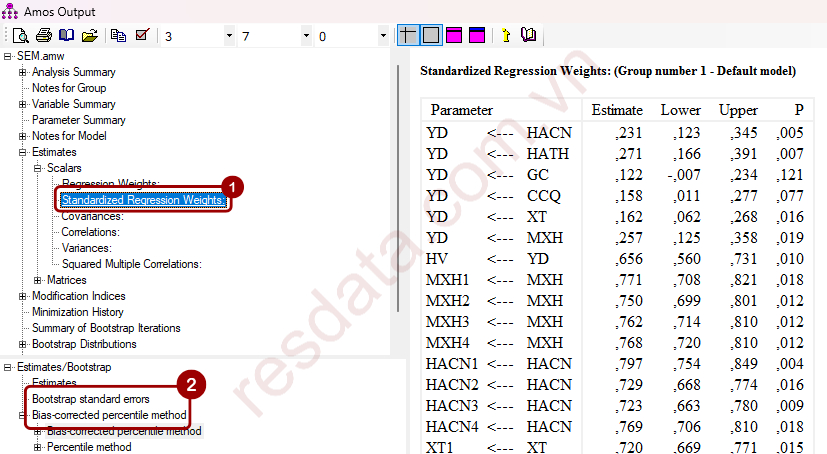
a. Bootstrap standard errors
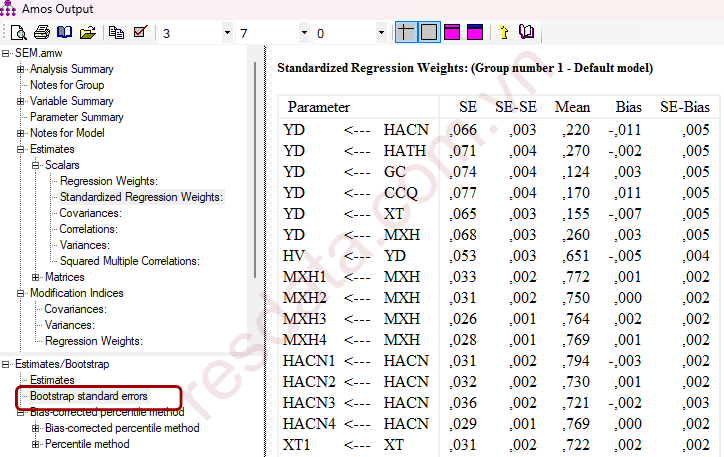
Bảng Bootstrap standard errors cung cấp thông tin về sai số chuẩn Bootstrap (SE), sai số chuẩn của sai số chuẩn (SE-SE), giá trị trung bình Bootstrap (Mean), độ chệch (Bias) và sai số chuẩn của độ chệch (SE-Bias) cho từng tham số trong mô hình.
| Chỉ số Bootstrap | Ý nghĩa và cách đọc trong AMOS |
|---|---|
|
SE (Bootstrap Standard Error) |
SE thể hiện mức độ biến thiên của hệ số hồi quy giữa các mẫu Bootstrap trong AMOS. SE nhỏ → hệ số hồi quy ổn định, kết quả ước lượng đáng tin cậy. SE lớn → ước lượng kém ổn định, nhạy cảm với dữ liệu mẫu. Trong bảng kết quả, SE dao động khoảng 0,026–0,077, cho thấy các hệ số hồi quy trong mô hình SEM tương đối ổn định khi chạy Bootstrap. |
|
SE-SE (Standard Error of SE) |
SE-SE phản ánh mức độ ổn định của chính sai số chuẩn Bootstrap. SE-SE nhỏ → sai số chuẩn Bootstrap được ước lượng đáng tin cậy. Các giá trị SE-SE đều rất nhỏ (≈ 0,001–0,004), cho thấy kết quả Bootstrap trong AMOS có độ ổn định cao. |
|
Mean (Bootstrap Mean) |
Mean là giá trị trung bình của hệ số hồi quy thu được từ tất cả các mẫu Bootstrap. So sánh Mean với hệ số ước lượng ban đầu giúp đánh giá mức độ bền vững của tham số. Mean của các đường dẫn (ví dụ: YD ← HACN, YD ← HATH, HV ← YD) xấp xỉ với Estimate, cho thấy mô hình SEM không bị biến dạng khi áp dụng Bootstrap. |
|
Bias (Độ chệch) |
Bias phản ánh độ lệch giữa trung bình Bootstrap và hệ số ước lượng ban đầu. Công thức: Bias = Mean − Estimate Bias ≈ 0 → hệ số hồi quy không bị lệch. Các giá trị Bias đều rất nhỏ, cho thấy mô hình SEM trong AMOS đạt độ ổn định tốt. |
| SE-Bias |
SE-Bias là sai số chuẩn của độ chệch, dùng để đánh giá mức độ ổn định của Bias. Không dùng để kiểm định giả thuyết. SE-Bias đều nhỏ (khoảng 0,002–0,005), cho thấy Bias được ước lượng nhất quán giữa các mẫu Bootstrap. |
Dựa trên các chỉ số SE, SE-SE, Mean, Bias và SE-Bias, có thể kết luận rằng các tham số trong mô hình SEM có độ ổn định cao và kết quả Bootstrap là đáng tin cậy, phù hợp để sử dụng cho kiểm định giả thuyết nghiên cứu.
b. Bias-corrected confidence intervals (Khoảng tin cậy hiệu chỉnh độ chệch)
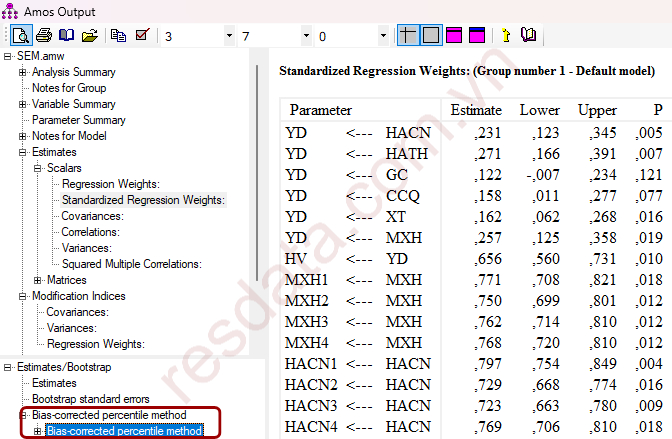
Nguyên tắc kiểm định
Khi sử dụng Bias-corrected confidence intervals (BC CI) trong Bootstrap SEM, việc kết luận giả thuyết không dựa vào công thức hay CR, mà dựa vào vị trí của giá trị 0 trong khoảng tin cậy.
-
Khoảng tin cậy không chứa 0 (Lower > 0 hoặc Upper < 0)
→ Mối quan hệ có ý nghĩa thống kê, giả thuyết được chấp nhận -
Khoảng tin cậy chứa 0
→ Mối quan hệ không có ý nghĩa thống kê, giả thuyết bị bác bỏ
Dựa trên bảng Bias-corrected confidence intervals:
-
Các mối quan hệ YD ← HACN, YD ← HATH, YD ← XT, YD ← MXH, HV ← YD đều có:
-
Lower > 0
-
Upper > 0
-
⇒ Khoảng tin cậy không chứa 0, cho thấy các mối quan hệ này có ý nghĩa thống kê theo Bootstrap.
-
Riêng mối quan hệ YD ← GC có:
-
Lower = −0,007
-
Upper = 0,234
-
⇒ Khoảng tin cậy chứa giá trị 0, do đó giả thuyết không được ủng hộ, mặc dù hệ số ML có thể vẫn có p-value nhỏ.
Kết quả Bias-corrected confidence intervals cho thấy phần lớn các mối quan hệ trong mô hình có khoảng tin cậy không chứa 0, do đó các giả thuyết tương ứng được chấp nhận. Những mối quan hệ có khoảng tin cậy chứa 0 sẽ bị bác bỏ, ngay cả khi kết quả ước lượng ML cho thấy có ý nghĩa thống kê.
3. Bác bỏ giả thuyết dựa trên công thức CR (Critical Ratio)
3.1 C.R = Bias / SE-Bias không có cơ sở học thuật chính thống
Hiện nay, trong một số bài viết hướng dẫn, video Youtube và cả luận văn thạc sĩ tại Việt Nam, có xuất hiện cách tính:
C.R = Bias / SE-Bias
sau đó so sánh với ngưỡng 1.96 (hoặc 2) để kết luận mối quan hệ trong mô hình SEM có hay không có ý nghĩa thống kê.
Cách làm này là SAI về mặt phương pháp luận.
Các tài liệu thường được trích dẫn như:
-
Anderson & Gerbing (1998)
-
Schumacker & Lomax (1996)
-
Byrne (2016)
Hoàn toàn không hề đề cập đến việc sử dụng công thức C.R = Bias / SE-Bias để kiểm định ý nghĩa quan hệ trong SEM.
Bạn có thể kiểm chứng trực tiếp bằng cách tra cứu bản PDF gốc của các tài liệu này,vkhông có bất kỳ chỗ nào sử dụng công thức trên để kết luận giả thuyết.
3.2 Bản chất thật sự của C.R (Critical Ratio) trong SEM
C.R (Critical Ratio) là:
C.R = Estimate / S.E
Đây chính là t-value, dùng để kiểm định xem hệ số ước lượng có khác 0 hay không.
Ví dụ:
-
Estimate = 0.241
-
SE = 0.036
C.R = 0.241 / 0.036 ≈ 6.7
Giá trị C.R này được đem so với phân phối Student, trong đó:
-
|C.R| ≥ 1.96 → p < 0.05 → hệ số khác 0 có ý nghĩa
-
|C.R| < 1.96 → p > 0.05 → hệ số không có ý nghĩa
Đây là C.R chuẩn, được AMOS sử dụng trong SEM ML.
3.3 Áp dụng công thức C.R = Bias / SE-Bias đang kiểm định điều gì?
Khi áp dụng công thức C.R = Bias / SE-Bias, bạn cần hiểu rằng công thức không hề kiểm định ý nghĩa của mối quan hệ trong mô hình SEM. Thực chất, phép tính này chỉ đang kiểm định độ chệch Bias có khác 0 hay không.
Trong đó, Bias là độ chênh lệch giữa hệ số hồi quy trung bình của các mẫu Bootstrap và hệ số hồi quy của mẫu gốc, còn SE-Bias là sai số chuẩn của độ chệch này. Nếu Bias nhỏ và tiến gần về 0, đó là dấu hiệu tốt cho thấy quá trình lấy mẫu Bootstrap ổn định và phân phối ước lượng không bị méo.
Tuy nhiên, Bias không phải là tiêu chí để chấp nhận hay bác bỏ giả thuyết trong SEM. Việc giá trị Bias/SE-Bias lớn hay nhỏ hoàn toàn không phản ánh ý nghĩa thống kê của mối quan hệ nhân quả giữa các biến trong mô hình. Do đó, sử dụng công thức này để kết luận mối quan hệ có ý nghĩa hay không là sai về mặt phương pháp.
Trong phân tích SEM với AMOS, Maximum Likelihood (ML) và Bootstrap là hai kỹ thuật đánh giá tác động trực tiếp có thể thay thế cho nhau, chứ không được sử dụng song song để kết luận cùng một mối quan hệ nhân quả trong cùng mô hình. Việc kết luận ý nghĩa quan hệ cần nhất quán theo một phương pháp kiểm định duy nhất.
Công thức C.R = Bias / SE-Bias tuy đúng về mặt toán học, nhưng không phải là tiêu chí kiểm định ý nghĩa thống kê của mối quan hệ trong SEM. Chỉ số này chỉ phản ánh việc độ chệch Bias có khác 0 hay không, nhằm đánh giá độ ổn định của quá trình lấy mẫu Bootstrap, chứ không dùng để chấp nhận hay bác bỏ giả thuyết nghiên cứu. Do đó, không có cơ sở phương pháp luận nào để chạy Bootstrap chỉ nhằm tính chỉ số C.R này.
Trong thực hành SEM hiện nay, Bootstrap chủ yếu được sử dụng để kiểm định tác động gián tiếp (biến trung gian) hoặc thay thế ML khi dữ liệu không phân phối chuẩn, thông qua Bias-corrected confidence intervals, thay vì dựa vào Bias hay Bias/SE-Bias để đánh giá tác động trực tiếp.
Vì vậy, việc vừa kết luận theo C.R (t-value) của ML, vừa tiếp tục sử dụng Bias/SE-Bias từ Bootstrap để đánh giá cùng một quan hệ trong cùng mô hình là không đúng chuẩn phương pháp nghiên cứu, và dễ dẫn đến sai lệch trong diễn giải kết quả SEM.
4. Lựa chọn SEM–Maximum Likelihood hay SEM–Bootstrap trong AMOS
4.1 Sự khác biệt giữa SEM–Maximum Likelihood và SEM–Bootstrap
Trong phân tích mô hình cấu trúc tuyến tính (SEM), SEM–Maximum Likelihood (ML) và SEM–Bootstrap đều được sử dụng để đánh giá ý nghĩa thống kê của các mối quan hệ nhân quả trong mô hình. Tuy nhiên, hai kỹ thuật này khác nhau về giả định dữ liệu, cách ước lượng tham số và cơ chế kiểm định, do đó không nên sử dụng song song để kết luận cùng một quan hệ.
Bảng dưới đây tóm tắt sự khác biệt cốt lõi giữa SEM–ML và SEM–Bootstrap trong AMOS:
| Yếu tố so sánh | SEM–Maximum Likelihood | SEM–Bootstrap |
|---|---|---|
| Phương pháp ước lượng | Maximum Likelihood (ML) | Bootstrap (lấy mẫu lặp lại có thay thế) |
| Giả định phân phối dữ liệu | Yêu cầu phân phối chuẩn đa biến | Không yêu cầu phân phối chuẩn |
| Cách ước lượng tham số | Ước lượng trực tiếp từ dữ liệu gốc | Ước lượng từ phân phối của các mẫu Bootstrap |
| Sai số chuẩn | Sai số chuẩn ML ước lượng từ dữ liệu gốc | Sai số chuẩn Bootstrap (SE, SE-Bias) |
| Khoảng tin cậy | Dựa trên phân phối chuẩn | Khoảng tin cậy Bootstrap (Bias-corrected confidence intervals) |
| Kiểm định ý nghĩa thống kê | Dựa vào C.R (t-value) và p-value | Dựa vào việc khoảng tin cậy Bootstrap có chứa 0 hay không |
| Trường hợp sử dụng phù hợp | Dữ liệu tiệm cận phân phối chuẩn, cỡ mẫu đủ lớn | Dữ liệu không phân phối chuẩn, cỡ mẫu vừa và nhỏ, hoặc kiểm định tác động trung gian |
4.2 Nếu dữ liệu không có phân phối chuẩn đa biến thì có nên dùng SEM-Maximum Likelihood?
Trong thực tế nghiên cứu, phần lớn dữ liệu không đảm bảo phân phối chuẩn đa biến (West et al., 1995; Byrne, 2016). Điều này đặt ra câu hỏi: SEM-Maximum Likelihood (ML) trong AMOS có còn sử dụng được hay không?
Về nguyên tắc, SEM-Maximum Likelihood giả định dữ liệu có phân phối chuẩn đa biến. Tuy nhiên, vi phạm giả định này không làm cho kết quả SEM trở nên vô dụng, bởi phương pháp ML có độ bền tương đối tốt đối với sai lệch phân phối, đặc biệt khi kích thước mẫu đủ lớn. Nhiều chỉ số phù hợp mô hình trong AMOS thường không bị ảnh hưởng nghiêm trọng bởi việc dữ liệu không chuẩn.
Điểm bị ảnh hưởng nhiều nhất khi dữ liệu không phân phối chuẩn là kiểm định ý nghĩa thống kê của hệ số hồi quy, vốn dựa trên giá trị C.R và P-value theo phân phối chuẩn. Khi mức độ vi phạm lớn, kết luận về ý nghĩa tác động có thể không còn đáng tin cậy.
• Nếu dữ liệu đảm bảo phân phối chuẩn đa biến → sử dụng SEM-Maximum Likelihood.
• Nếu dữ liệu không đảm bảo phân phối chuẩn đa biến → sử dụng SEM-Bootstrap để đánh giá ý nghĩa thống kê một cách phù hợp hơn.
5. Ứng dụng khác của kiểm định Bootstrap trong AMOS
Ngoài việc hỗ trợ xử lý dữ liệu không phân phối chuẩn, kiểm định Bootstrap trong AMOS còn được sử dụng rất phổ biến để phân tích biến trung gian (tác động gián tiếp) trong mô hình SEM.
Khi thực hiện Bootstrap, AMOS cho phép đánh giá ý nghĩa thống kê của quan hệ trung gian thông qua hai tiêu chí chính:
Thứ nhất, khoảng tin cậy Bootstrap của tác động gián tiếp.
Dựa vào khoảng tin cậy Bootstrap (thường là Bias-corrected confidence intervals). Nếu khoảng tin cậy không chứa giá trị 0, có thể kết luận rằng tác động trung gian có ý nghĩa thống kê.
Thứ hai, giá trị Sig. Bootstrap của tác động gián tiếp.
So sánh giá trị Sig. Bootstrap với mức ý nghĩa lựa chọn (thường là 0.05). Nếu Sig. < 0.05, quan hệ trung gian được xem là có ý nghĩa thống kê.
Trong thực hành SEM, khoảng tin cậy Bootstrap thường được ưu tiên hơn Sig., vì đây là phương pháp khuyến nghị trong các nghiên cứu hiện đại khi kiểm định tác động gián tiếp.
Xem hướng dẫn chi tiết về xử lý biến trung gian trong AMOS bằng Bootstrap để hiểu rõ cách đọc khoảng tin cậy Bootstrap và kết luận tác động gián tiếp.
-------------------
Nội dung được Resdata biên soạn dựa trên kinh nghiệm trực tiếp trong quá trình xử lý và phân tích dữ liệu cho nhiều đề tài nghiên cứu khác nhau. Trong trường hợp bạn gặp khó khăn khi thao tác AMOS, chưa tự tin trong việc đọc và diễn giải kết quả, hoặc cần hỗ trợ để hoàn thiện mô hình nghiên cứu đúng hướng và đúng chuẩn học thuật, dịch vụ AMOS tại Resdata sẵn sàng đồng hành và hỗ trợ bạn giúp bạn vượt qua mọi deadline cận kề nhất.
Resdata hỗ trợ bạn những gì?
✅ Tư vấn & định hướng toàn bộ quy trình xử lý dữ liệu AMOS: Rà soát thang đo, phát hiện và xử lý các biến không phù hợp, đồng thời định hướng từng bước phân tích (Cronbach’s Alpha, EFA, hồi quy/SEM…) theo đúng bản chất dữ liệu, bối cảnh nghiên cứu và mục tiêu đề tài, giúp kết quả phản ánh thực tế nghiên cứu và đáp ứng yêu cầu học thuật.
✅ Hỗ trợ SPSS 1 kèm 1 qua ultraview: Hướng dẫn chi tiết từng bước thực hành và cách viết nhận xét chuẩn học thuật.
✅ Xử lý nhanh – đúng chuẩn: Xử lý kết quả trong ngày Phù hợp cho khóa luận, luận văn, luận án và bài báo khoa học.
✅ Cam kết chỉnh sửa theo góp ý của giảng viên/hội đồng cho đến khi đạt yêu cầu.
Nếu bạn đang gặp phải các tình huống trên và chưa tìm được hướng xử lý phù hợp, đừng ngần ngại liên hệ ngay: Hotline: 0907 786 895.
Resdata luôn sẵn sàng đồng hành cùng bạn với phương châm Nhanh chóng – Tin cậy – Bảo mật – Chi phí hợp lý.






