Phân tích SEM trong AMOS: Kiểm định giả thuyết và đọc hệ số chuẩn hóa
Phân tích SEM trong AMOS là phương pháp thống kê nâng cao dùng để kiểm định mô hình nghiên cứu và các giả thuyết thông qua việc đánh giá mối quan hệ nhân quả giữa các biến tiềm ẩn. Bài viết hướng dẫn cách kiểm định giả thuyết, đọc hệ số chuẩn hóa và đánh giá độ phù hợp mô hình trong AMOS một cách dễ hiểu - chi tiết.
1. Mục đích của phân tích mô hình cấu trúc tuyến tính SEM
-
Đánh giá độ phù hợp của mô hình SEM thông qua các chỉ số độ phù hợp mô hình (Model Fit) như: Chi-square/df, CFI, TLI, GFI, RMSEA,…, từ đó xác định mức độ phù hợp giữa mô hình lý thuyết và dữ liệu thực tế.
-
Kiểm định ý nghĩa thống kê của các mối quan hệ trong mô hình, bao gồm các quan hệ tác động trực tiếp và các quan hệ trung gian, qua đó xác định các giả thuyết nghiên cứu có được chấp nhận hay không.
-
Đánh giá chiều và mức độ tác động của các biến trong mô hình, dựa trên hệ số chuẩn hóa, giúp xác định mối quan hệ cùng chiều hay ngược chiều, cũng như mức ảnh hưởng mạnh, trung bình hay yếu giữa các nhân tố.
2. Xây dựng mô hình cấu trúc tuyến tính SEM
Trong bài viết hướng dẫn phân tích CFA trên AMOS, mô hình nghiên cứu đã được trình bày ở phần trước tiếp tục được sử dụng để thực hiện phân tích.
Mô hình bao gồm các biến tiềm ẩn (latent variables) và biến quan sát (observed variables) như sau:
| Biến tiềm ẩn | Biến quan sát (Observed variables) |
|---|---|
| MXH | MXH1, MXH2, MXH3, MXH4 |
| HACN | HACN1, HACN2, HACN3, HACN4 |
| XT | XT1, XT2, XT3, XT4 |
| HATH | HATH1, HATH2, HATH3, HATH4 |
| CCQ | CCQ3, CCQ4, CCQ5 |
| HV | HV1, HV2, HV3 |
| GC | GC2, GC3, GC4 |
| YD | YD1, YD2, YD3 |
Trong đó CCQ3, CCQ4, GC1 bị loại ở bước Cronbach's Alpha nên không sử dụng lại ở CFA.
Mỗi biến tiềm ẩn đại diện cho một khía cạnh lý thuyết, và các biến quan sát thể hiện các câu hỏi khảo sát đo lường khía cạnh đó.
Nghiên cứu này tập trung xem xét 7 giả thuyết, nhằm làm rõ mức độ ảnh hưởng của các yếu tố đến ý định mua và hành vi mua mỹ phẩm.
-
H1: Hình ảnh cá nhân (HACN) có tác động đến Ý định mua (YD)
-
H2: Hình ảnh thương hiệu (HATH) có tác động đến Ý định mua (YD)
-
H3: Giá cả (GC) có tác động đến Ý định mua (YD)
-
H4: Chuẩn chủ quan (CCQ) có tác động đến Ý định mua (YD)
-
H5: Xúc tiến bán hàng (XT) có tác động đến Ý định mua (YD)
-
H6: Mạng xã hội (MXH) có tác động đến Ý định mua (YD)
-
H7: Ý định mua (YD) có tác động đến Hành vi mua mỹ phẩm (HV)
2.1 Vẽ mô hình SEM từ mô hình CFA trong AMOS
Nếu trước đó bạn đã thực hiện phân tích CFA, bạn hoàn toàn có thể tận dụng lại mô hình CFA để chuyển sang SEM, thay vì phải vẽ lại từ đầu. Cách làm này giúp tiết kiệm thời gian và đảm bảo mô hình phân tích được thực hiện nhất quán.
Tại giao diện diagram CFA trong AMOS, bạn thực hiện:
-
Chọn File → Save As
-
Đặt tên file mới, ví dụ: SEM
File mới này sẽ được sử dụng để chỉnh sửa và chạy mô hình SEM.
Trước khi chỉnh sửa mô hình, bạn nên xem mô hình hiển thị theo hướng nào cho dễ nhìn. Nếu mô hình gọn và vừa với khổ giấy dọc thì có thể giữ nguyên. Trường hợp mô hình trải rộng, nhiều biến, hiển thị khổ giấy ngang sẽ dễ quan sát hơn, khi đó bạn nên đổi khổ giấy trước khi tiếp tục phân tích.
Cách đổi khổ giấy: Trên cửa sổ AMOS, vào View → Interface Properties
.jpg)
Chọn lại hướng hiển thị phù hợp với mô hình nghiên cứu
.jpg)
Sử dụng công cụ xóa đối tượng trong AMOS để loại bỏ toàn bộ các mũi tên hai chiều (Covariance) giữa các biến tiềm ẩn. Trường hợp chưa quen với các công cụ trên AMOS, bạn xem video hướng dẫn trong bài viết vẽ diagram CFA, SEM trong AMOS .
.jpg)
Sau khi xóa các mũi tên Covariance, bạn sử dụng các công cụ di chuyển, căn chỉnh và xoay cấu trúc để sắp xếp lại vị trí các biến tiềm ẩn theo đúng bố cục của mô hình lý thuyết. Tiếp theo, dùng công cụ Title để chèn các chỉ số Model Fit trực tiếp lên diagram. Khi bố trí mô hình, nên chừa khoảng trống bên phải các biến độc lập để thuận tiện cho việc vẽ các mũi tên hai chiều (Covariance) ở bước sau.
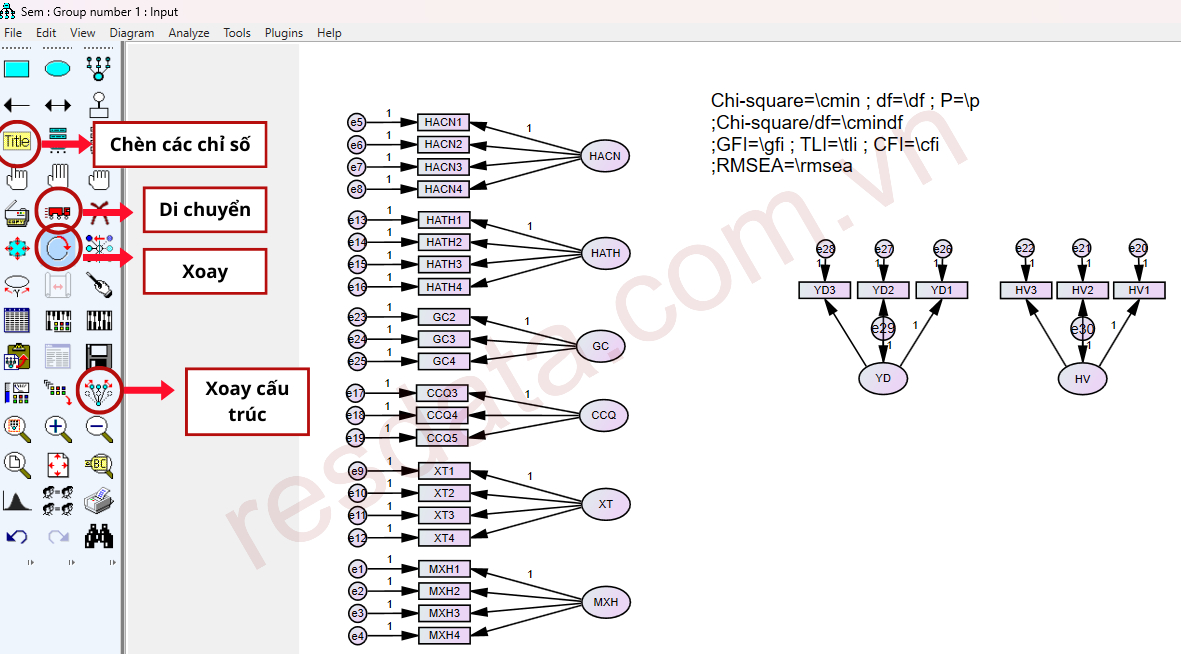
Sử dụng mũi tên hai chiều (Covariance) để nối các biến tiềm ẩn đóng vai trò độc lập với nhau. Biến độc lập là biến chỉ tác động đến biến khác và không nhận tác động ngược lại trong mô hình. Việc vẽ mũi tên hai chiều giúp AMOS xem xét mối tương quan giữa các biến độc lập khi chúng cùng tác động đến một biến phụ thuộc. Nếu không vẽ Covariance, AMOS sẽ chỉ phân tích các tác động trực tiếp và bỏ qua mối liên hệ giữa các biến độc lập, điều này có thể làm kết quả phân tích kém chính xác.
Khi vẽ mũi tên Covariance, bạn nên điều chỉnh hướng vẽ sao cho đường cong nằm ở khoảng trống, tránh chồng lên các đối tượng khác trong diagram. Sau khi hoàn tất, sử dụng công cụ làm đẹp (Touch up a variable) để căn chỉnh và tối ưu hiển thị mô hình.
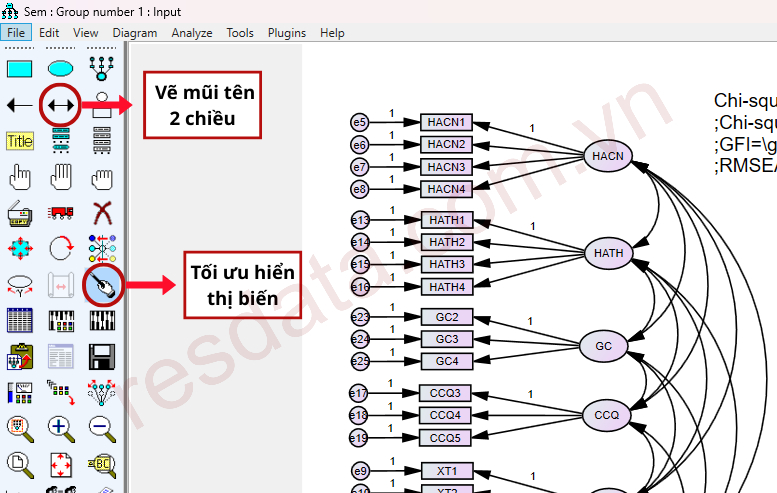
Tiếp theo, tiến hành vẽ các mũi tên một chiều để biểu diễn mối quan hệ tác động giữa các biến trong mô hình nghiên cứu. Trong quá trình vẽ, bạn có thể kết hợp sử dụng công cụ làm đẹp (Touch up a variable) và nhấp lần lượt vào các biến tiềm ẩn để căn chỉnh vị trí, tối ưu hiển thị, giúp mô hình gọn gàng và dễ quan sát hơn.
Sau khi hoàn tất các mối quan hệ tác động, cần lưu ý vai trò của các biến trong mô hình. Cụ thể, YD là biến vừa nhận tác động từ các biến khác, vừa tiếp tục tác động đến biến HV, trong khi HV là biến phụ thuộc cuối cùng. Vì vậy, khi xây dựng mô hình SEM trên AMOS, cần khai báo phần dư (sai số) cho cả hai biến YD và HV.
Để thêm phần dư, bạn chọn biểu tượng phần dư/sai số, sau đó nhấp chuột vào biến YD. Khi nhấp lần đầu, phần dư sẽ xuất hiện theo hướng mặc định; nếu vị trí chưa phù hợp, tiếp tục nhấp chuột để xoay hướng phần dư cho đến khi hiển thị hợp lý thì dừng lại.
Cuối cùng, thực hiện tương tự cho biến HV, đảm bảo phần dư được bố trí gọn gàng, không chồng chéo với các mũi tên tác động trong mô hình.
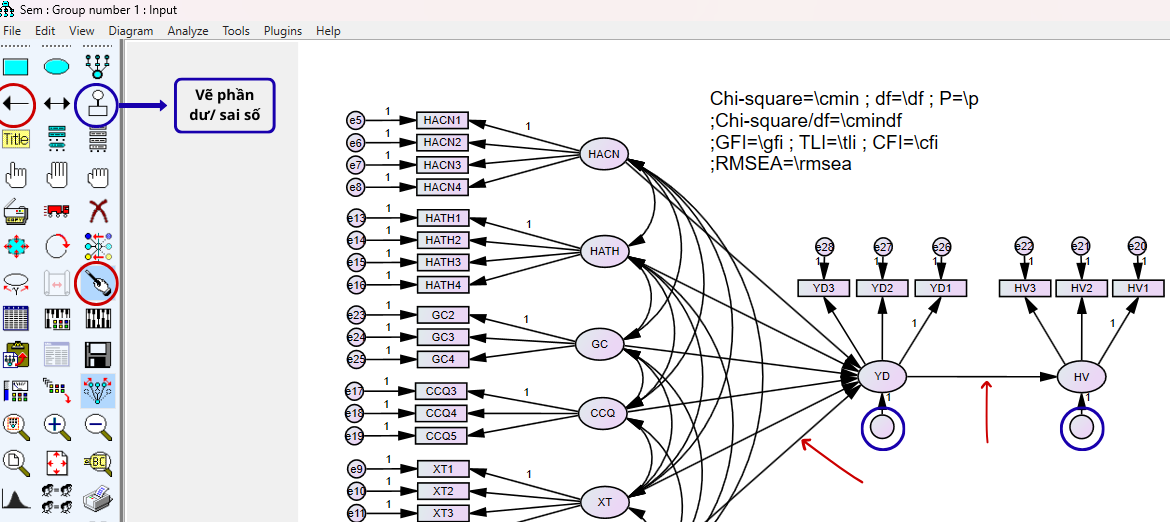
Sau khi gán phần dư cho hai biến YD và HV, các phần dư này chưa được đặt tên. Vì vậy, cấn khai báo tên cho các phần dư trước khi chạy mô hình. Cách đơn giản nhất là nhấp đôi chuột vào từng phần dư và đặt tên thủ công. Hoặc có thể đặt tên hàng loạt bằng plugin trong AMOS bằng cách vào Plugins → Name Unobserved Variables.
.jpg)
Chúng ta đã hoàn tất việc vẽ mô hình và thu được diagram SEM hoàn chỉnh như hình dưới đây:
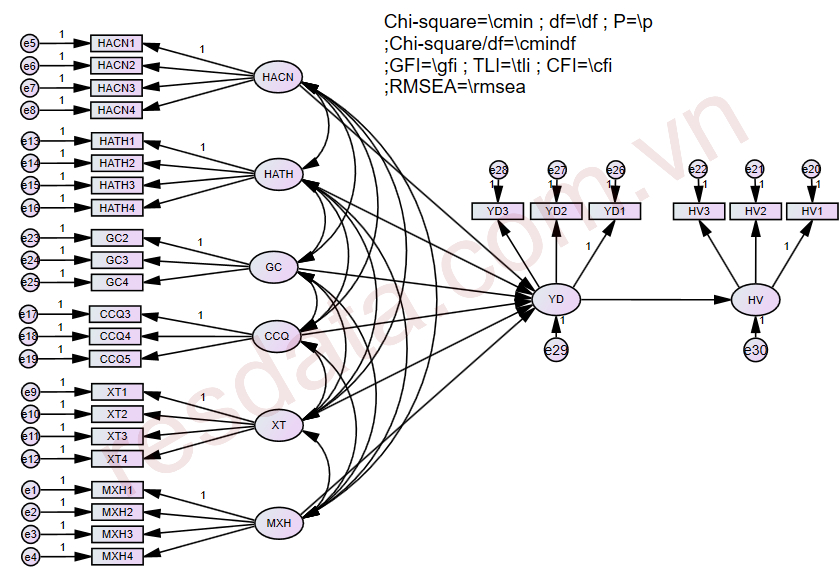
2.2 Thực hiện phân tích SEM trên AMOS
Bước 1: Khai báo dữ liệu SPSS cho AMOS
Để AMOS nhận diện dữ liệu, thực hiện các bước sau: Trên thanh menu, chọn File → Data Files
.jpg)
Nhấn Browse và chọn file dữ liệu SPSS đã chuẩn bị (ví dụ: DATA_THUCHANH_AMOS.sav)

Nhấn OK để hoàn tất liên kết dữ liệu
.jpg)
Bước 2: Thiết lập phân tích SEM trong AMOS
Từ giao diện AMOS, chọn biểu tượng Analysis Properties để cài đặt các tùy chọn cho SEM.
.jpg)
Chuyển sang thẻ Output và tích chọn các mục quan trọng:
-
Standardized Estimates: hiển thị hệ số chuẩn hóa, giúp đánh giá trọng số giữa biến tiềm ẩn và biến quan sát.
-
Squared Multiple Correlations (R²): hiển thị mức độ giải thích của các biến quan sát bởi biến tiềm ẩn.
-
Residual Moments: cung cấp thông tin về phần dư giữa giá trị dự đoán và giá trị quan sát.
-
Modification Indices (MI): cho biết những điểm yếu trong mô hình, hỗ trợ điều chỉnh để tăng độ phù hợp. Xem chi tiết cách sử dụng chỉ số này tại bài viết Chỉ số MI - Modification Indices trong AMOS.
.jpg)
Bước 3: Thực hiện phân tích SEM
Chọn biểu tượng Calculate Estimates để AMOS chạy phân tích SEM.
.jpg)
Sau khi chạy xong, bạn sẽ thấy các hệ số cơ bản được hiển thị trực tiếp trên diagram SEM. Để xem kết quả chi tiết toàn bộ, nhấn vào View Text:
.png)
3. Kết quả phân tích SEM trong AMOS
Khi đọc kết quả phân tích SEM trên AMOS, chúng ta tập trung vào ba nhóm kết quả chính gồm: bảng hệ số tác động chưa chuẩn hóa (Regression Weights), bảng hệ số tác động chuẩn hóa (Standardized Regression Weights) và bảng hệ số xác định (Squared Multiple Correlations).
3.1 Bảng hệ số tác động chưa chuẩn hóa (Regression Weights)
Bảng Regression Weights cung cấp các thông tin quan trọng để đánh giá mức độ và ý nghĩa thống kê của các mối quan hệ trong mô hình SEM, bao gồm:
-
Estimate: Hệ số hồi quy chưa chuẩn hóa. Dấu dương (+) thể hiện tác động cùng chiều, dấu âm (–) thể hiện tác động ngược chiều. Giá trị này có thể thay đổi tùy theo cách cố định tham số trong mô hình.
-
S.E (Standard Error): Sai số chuẩn của hệ số hồi quy.
-
C.R (Critical Ratio): Giá trị kiểm định tương đương thống kê t, dùng để đánh giá ý nghĩa của hệ số hồi quy. Tuy nhiên, việc tra bảng t không thuận tiện trong thực hành.
-
P giá trị p-value (sig) : Giá trị xác định ý nghĩa thống kê của mối quan hệ. Với mức ý nghĩa 5% (0.05), nếu P < 0.05 thì mối quan hệ có ý nghĩa thống kê; ngược lại, nếu P > 0.05 thì mối quan hệ không có ý nghĩa thống kê.
Dựa vào bảng Regression Weights trong kết quả mô hình, chúng ta sẽ xác định các giả thuyết được chấp nhận hay bị bác bỏ.
.jpg)
Bảng Regression Weights hiển thị toàn bộ các mối quan hệ tác động trong mô hình SEM, bao gồm cả quan hệ giữa các biến tiềm ẩn với nhau và quan hệ giữa biến tiềm ẩn với các biến quan sát. Khi đọc kết quả, chúng ta chỉ tập trung vào các mối quan hệ giữa các biến tiềm ẩn trong mô hình nghiên cứu, các dòng liên quan đến biến quan sát (ví dụ MXH1 <--- MXH) có thể bỏ qua.
Dựa vào bảng kết quả, có thể thấy tất cả các mối quan hệ tác động giữa các biến tiềm ẩn đều có ý nghĩa thống kê, do giá trị p-value đều nhỏ hơn 0.05. Trong đó, ký hiệu *** trong AMOS đại diện cho p-value = 0.000, cho thấy mức ý nghĩa thống kê rất cao.
Ngoài ra, các hệ số hồi quy đều mang dấu dương, chứng tỏ các mối quan hệ trong mô hình là tác động thuận chiều.
Căn cứ vào kết quả bảng Regression Weights, các giả thuyết nghiên cứu được kết luận như sau:
-
H1: Hình ảnh cá nhân (HACN) có tác động đến Ý định mua (YD) → Chấp nhận
-
H2: Hình ảnh thương hiệu (HATH) có tác động đến Ý định mua (YD) → Chấp nhận
-
H3: Giá cả (GC) có tác động đến Ý định mua (YD) → Chấp nhận
-
H4: Chuẩn chủ quan (CCQ) có tác động đến Ý định mua (YD) → Chấp nhận
-
H5: Xúc tiến bán hàng (XT) có tác động đến Ý định mua (YD) → Chấp nhận
-
H6: Mạng xã hội (MXH) có tác động đến Ý định mua (YD) → Chấp nhận
-
H7: Ý định mua (YD) có tác động đến Hành vi mua mỹ phẩm (HV) → Chấp nhận
Như vậy, cả 7 giả thuyết trong mô hình nghiên cứu đều được chấp nhận dựa trên kết quả phân tích SEM thông qua bảng Regression Weights.
3.2 Bảng hệ số tác động chuẩn hóa (Standardized Regression Weights)
Bảng Standardized Regression Weights chỉ hiển thị một cột giá trị duy nhất là Estimate, đây chính là hệ số tác động chuẩn hóa.
-
Hệ số mang dấu dương (+) thể hiện tác động thuận chiều
-
Hệ số mang dấu âm (–) thể hiện tác động nghịch chiều
Ý nghĩa quan trọng nhất của hệ số chuẩn hóa là giúp so sánh mức độ tác động mạnh hay yếu giữa các biến độc lập cùng tác động lên một biến phụ thuộc. Biến nào có giá trị tuyệt đối của hệ số chuẩn hóa lớn hơn thì biến đó có mức ảnh hưởng mạnh hơn.
Dựa vào mô hình nghiên cứu ở trên, bảng Standardized Regression Weights được sử dụng để đánh giá mức độ tác động của từng yếu tố trong mô hình SEM.
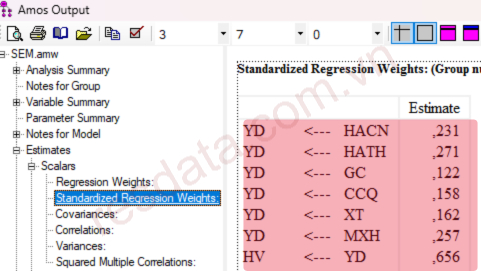
→ Thứ tự mức độ tác động từ mạnh đến yếu của các biến độc lập lên biến YD (Ý định) lần lượt là: HATH > MXH > HACN > XT > CCQ > GC.
Việc xếp hạng này được thực hiện dựa trên giá trị tuyệt đối của hệ số chuẩn hóa (Estimate), tức là so sánh độ lớn hệ số, không xét dấu dương hay âm. Biến nào có hệ số chuẩn hóa lớn hơn thì mức ảnh hưởng lên YD mạnh hơn.
→ Đối với biến HV (Hành vi), mô hình cho thấy chỉ có một biến độc lập là YD tác động trực tiếp với hệ số chuẩn hóa khá lớn (Estimate = 0.656). Điều này cho thấy Ý định có vai trò ảnh hưởng mạnh đến Hành vi.
Trong trường hợp chỉ có một biến độc lập tác động lên biến phụ thuộc, chúng ta không cần thực hiện so sánh mức độ tác động, mà chỉ cần kết luận mối quan hệ đó có ý nghĩa và mức ảnh hưởng mạnh hay yếu dựa vào giá trị hệ số chuẩn hóa.
3.3 Bảng hệ số xác định (Squared Multiple Correlations)
Bảng Squared Multiple Correlations chỉ cung cấp một cột giá trị duy nhất là Estimate, đây chính là hệ số xác định R² (R bình phương).
Giá trị R² dao động từ 0 đến 1, phản ánh mức độ các biến độc lập giải thích được biến phụ thuộc trong mô hình.
-
R² càng gần 1 → mức độ giải thích càng cao
-
R² càng gần 0 → mức độ giải thích càng thấp
Trong trường hợp R² lớn hơn 1, mô hình có thể đang gặp lỗi, thường do dữ liệu sai hoặc hiện tượng cộng tuyến giữa các biến độc lập.
Ý nghĩa của R² là cho biết tổng mức độ ảnh hưởng của các biến độc lập lên một biến phụ thuộc. Vì vậy, mỗi biến phụ thuộc trong mô hình sẽ có một giá trị R² tương ứng.
Ví dụ, với mô hình trên có hai biến phụ thuộc là YD và HV, nên bảng kết quả sẽ hiển thị hai hệ số R² cho hai biến này.
Theo Hair và cộng sự (2017), rất khó đưa ra một ngưỡng cố định để đánh giá R² là cao hay thấp, vì giá trị này phụ thuộc vào độ phức tạp của mô hình và lĩnh vực nghiên cứu. Do đó, quan điểm cho rằng R² phải lớn hơn 0.5 mới đạt là không chính xác và không nên áp dụng máy móc.
Dựa trên mô hình nghiên cứu ở trên, bảng Squared Multiple Correlations được sử dụng để đánh giá mức độ giải thích của mô hình SEM đối với từng biến phụ thuộc.
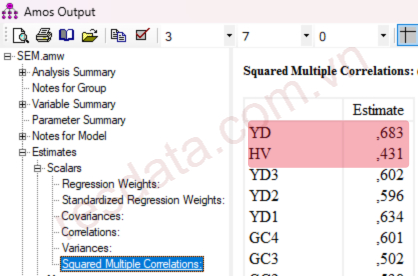
→ Giá trị R² của biến YD là 0.683 (68.3%). Điều này cho thấy các biến độc lập HACN, HATH, GC, CCQ, XT và MXH giải thích được 68.3% sự biến thiên của Ý định (YD). Nói cách khác, mô hình có khả năng giải thích khá tốt sự hình thành của YD thông qua các yếu tố này.
→ Giá trị R² của biến HV là 0.431 (43.1%). Điều này có nghĩa là biến Ý định (YD) giải thích được 43.1% sự biến thiên của Hành vi (HV). Phần còn lại của HV đến từ các yếu tố khác chưa được đưa vào mô hình.
Như vậy, có thể thấy mô hình SEM có mức độ giải thích tương đối tốt đối với biến YD, trong khi mức độ giải thích đối với HV ở mức trung bình, phù hợp với đặc điểm các mô hình hành vi trong nghiên cứu xã hội và marketing.
Kết Luận
Phân tích SEM trong AMOS là công cụ hiệu quả giúp kiểm định giả thuyết và đánh giá mối quan hệ giữa các biến trong mô hình nghiên cứu. Thông qua việc đọc hệ số tác động, hệ số chuẩn hóa và R², người nghiên cứu có thể xác định mức độ ảnh hưởng và khả năng giải thích của mô hình.
Kết quả cho thấy mô hình SEM phù hợp với dữ liệu, các mối quan hệ có ý nghĩa thống kê được xác nhận rõ ràng, đồng thời vai trò của từng biến được thể hiện cụ thể. Việc thực hiện CFA trước khi chạy SEM là điều kiện cần để đảm bảo kết quả phân tích đáng tin cậy.
Hy vọng bài viết giúp bạn hiểu và áp dụng phân tích SEM trong AMOS đúng cách, phục vụ hiệu quả cho nghiên cứu và thực hành phân tích dữ liệu.
-------------------
Nội dung được Resdata biên soạn dựa trên kinh nghiệm trực tiếp trong quá trình xử lý và phân tích dữ liệu cho nhiều đề tài nghiên cứu khác nhau. Trong trường hợp bạn gặp khó khăn khi thao tác AMOS, chưa tự tin trong việc đọc và diễn giải kết quả, hoặc cần hỗ trợ để hoàn thiện mô hình nghiên cứu đúng hướng và đúng chuẩn học thuật, dịch vụ AMOS tại Resdata sẵn sàng đồng hành và hỗ trợ bạn giúp bạn vượt qua mọi deadline cận kề nhất.
Resdata hỗ trợ bạn những gì?
✅ Tư vấn & định hướng toàn bộ quy trình xử lý dữ liệu AMOS: Rà soát thang đo, phát hiện và xử lý các biến không phù hợp, đồng thời định hướng từng bước phân tích (Cronbach’s Alpha, EFA, hồi quy/SEM…) theo đúng bản chất dữ liệu, bối cảnh nghiên cứu và mục tiêu đề tài, giúp kết quả phản ánh thực tế nghiên cứu và đáp ứng yêu cầu học thuật.
✅ Hỗ trợ SPSS 1 kèm 1 qua ultraview: Hướng dẫn chi tiết từng bước thực hành và cách viết nhận xét chuẩn học thuật.
✅ Xử lý nhanh – đúng chuẩn: Xử lý kết quả trong ngày Phù hợp cho khóa luận, luận văn, luận án và bài báo khoa học.
✅ Cam kết chỉnh sửa theo góp ý của giảng viên/hội đồng cho đến khi đạt yêu cầu.
Nếu bạn đang gặp phải các tình huống trên và chưa tìm được hướng xử lý phù hợp, đừng ngần ngại liên hệ ngay: Hotline: 0907 786 895.
Resdata luôn sẵn sàng đồng hành cùng bạn với phương châm Nhanh chóng – Tin cậy – Bảo mật – Chi phí hợp lý.






