Hướng dẫn đánh giá mô hình cấu trúc SEM trên SMARTPLS 3
Trình tự và mục đích các bước phân tích trong sem trên phần mềm AMOS
Trong nghiên cứu định lượng, đặc biệt là các đề tài luận văn và khóa luận kinh tế – quản trị, SEM-PLS trên SmartPLS 3 đang được sinh viên và học viên cao học sử dụng ngày càng phổ biến. Tuy nhiên, trên thực tế, phần gây khó khăn nhất không phải là vẽ mô hình hay chạy lệnh trong phần mềm, mà là đánh giá và diễn giải mô hình cấu trúc SEM một cách chính xác và đúng chuẩn học thuật. Rất nhiều bài nghiên cứu bị đánh giá thấp do hiểu sai hệ số tác động, đọc nhầm chỉ số R² hoặc kết luận giả thuyết chưa thuyết phục. Bài viết này sẽ giúp bạn nắm rõ cách đánh giá mô hình cấu trúc SEM trên SmartPLS 3, hiểu đúng các chỉ số quan trọng và biết cách trình bày kết quả sao cho có thể sử dụng trực tiếp trong luận văn.
1. Đánh giá mô hình cấu trúc SEM trên SMARTPLS 3 là gì?
Đánh giá mô hình cấu trúc SEM (Structural Model Assessment) là quá trình kiểm tra mối quan hệ nhân quả giữa các biến tiềm ẩn trong mô hình nghiên cứu, sau khi mô hình đo lường (outer model) đã đạt yêu cầu.
Trong PLS-SEM (SMARTPLS 3), mô hình cấu trúc tập trung trả lời các câu hỏi:
-
Biến độc lập có tác động đến biến phụ thuộc hay không?
-
Mức độ tác động mạnh hay yếu?
-
Mô hình giải thích được bao nhiêu phần trăm sự biến thiên của biến phụ thuộc?
-
Mô hình có khả năng dự báo hay không?
Ví dụ đơn giản:
Nếu nghiên cứu của bạn xem xét Chất lượng dịch vụ → Sự hài lòng → Ý định sử dụng, thì đánh giá mô hình cấu trúc giúp xác định các giả thuyết này có được dữ liệu ủng hộ hay không.
2. Tổng quan mô hình cấu trúc SEM trong SMARTPLS 3
Để đánh giá mô hình cấu trúc trên SMARTPLS 3, chúng ta xem xét các yếu tố:
- Tính cộng tuyến của các biến độc lập (inner VIF).
- Ý nghĩa các quan hệ tác động trong mô hình (Path Coefficients).
- Đánh giá hệ số xác định R bình phương (R square).
- Đánh giá hệ số tác động f bình phương (f square).
Mỗi biến tiềm ẩn trong mô hình được đo thông qua tập hợp biến quan sát:
| Nhân tố | Ký hiệu | Biến quan sát |
|---|---|---|
| Bảo mật | BM | BM1, BM2, BM3, BM4 |
| Sự hài lòng của khách hàng | HL | HL1, HL2, HL3, HL4 |
| Ý định tiếp tục mua sắm trực tuyến | YD | YD1, YD2, YD3 |
| Nhận thức về giá cả | GC | GC1, GC2, GC3, GC4, GC5 |
| Nhận thức tính hữu ích | HI | HI1, HI2, HI3, HI4, HI5 |
| Nhận thức tính dễ sử dụng | SD | SD1, SD2, SD3, SD4 |
Để biểu diễn mô hình nghiên cứu lý thuyết lên diagram SMARTPLS 3. Cách sử dụng các công cụ của phần mềm để vẽ diagram bạn xem tại Hướng dẫn chi tiết cách sử dụng SmartPLS 3.
3. Phân tích Bootstrap trên SMARTPLS 3
Để đánh giá mô hình cấu trúc SEM trên SMARTPLS 3, bạn bắt buộc phải thực hiện phân tích Bootstrapping. Tuy nhiên, trước khi chạy bootstrap, cần đảm bảo rằng mô hình đo lường đã đạt yêu cầu. Ở bước đánh giá mô hình đo lường, nếu có các biến quan sát không thỏa mãn điều kiện (như hệ số tải thấp hoặc không đạt độ tin cậy), bạn cần loại bỏ những biến này khỏi mô hình.
Sau khi loại biến, hãy vẽ lại sơ đồ mô hình (diagram) trong SMARTPLS để mô hình phản ánh đúng cấu trúc cuối cùng. Chỉ khi mô hình đã được hiệu chỉnh hoàn chỉnh, bạn mới tiến hành chạy Bootstrapping nhằm kiểm định các mối quan hệ giữa các biến tiềm ẩn và đánh giá mô hình cấu trúc. Cách làm này giúp kết quả phân tích chính xác, nhất quán và phù hợp với yêu cầu của luận văn cũng như bài nghiên cứu khoa học.
Để thực hiện phân tích bootstrap trên SMARTPLS, tại giao diện diagram, chọn Calculate > Bootstrap.
.jpg)
Cửa sổ Bootstrapping xuất hiện, tiến hành phân tích như sau:
.jpg)
Thiết lập Bootstrapping trong SMARTPLS
- Subsamples: Là số lần lấy mẫu Bootstrap, thường sử dụng 1.000 hoặc 5.000 để đảm bảo độ tin cậy của kết quả.
- Bootstrapping Type: SMARTPLS mặc định dùng Basic Bootstrapping, cho phép xuất các kết quả cần thiết như Path Coefficients, Indirect Effects, Total Effects, Outer Loadings và Outer Weights. Trường hợp cần đầy đủ toàn bộ chỉ số, có thể chọn Complete Bootstrapping, tuy nhiên cách này tốn nhiều thời gian và tài nguyên máy tính, nên không khuyến nghị nếu không thật sự cần thiết.
- Confidence Interval Method: Giữ mặc định Bias-Corrected and Accelerated (BCa) vì đây là phương pháp cho kết quả ổn định và chính xác nhất.
- Test Type: Chọn Two-tailed để kiểm định hai phía.
- Significance Level: Mức ý nghĩa thống kê, thường đặt 0.05 (5%), có thể điều chỉnh lên 10% hoặc xuống 1% tùy mục tiêu nghiên cứu.
Sau đó nhấp vào Start Calculation để tiến hành phân tích bootstrap trên SMARTPLS.
.jpg)
Output kết quả Boostrapping xuất hiện, chúng ta sẽ quan tâm đến 3 mục như ảnh bên dưới.
- Mục số 1, Export to Excel, Web, R để chúng ta xuất kết quả output ra file excel, file html hoặc định dạng của phần mềm R.
- Mục số 2 là giao diện hiển thị kết quả khi chúng ta nhấp vào các đầu mục kết quả ở mục 3.
- Mục số 3 là danh sách các kết quả phân tích mô hình.
4. Đánh giá mô hình cấu trúc SEM trên SMARTPLS 3
Phần này tập trung đánh giá mô hình cấu trúc SEM dựa trên kết quả phân tích định lượng bằng SMARTPLS. Các nội dung được trình bày theo trình tự đánh giá tiêu chuẩn, phù hợp với cách thực hiện trong các đề tài nghiên cứu và luận văn hiện nay.
4.1 Đánh giá các mối quan hệ tác động
Việc đánh giá các mối quan hệ tác động trong mô hình cấu trúc được thực hiện thông qua kết quả phân tích Bootstrap trên SMARTPLS. Tại giao diện kết quả, chọn Path Coefficients để xem các chỉ số liên quan.
.jpg)
Nghiên cứu chủ yếu quan tâm đến hai chỉ số là Original Sample và P Values để đánh giá mức độ và ý nghĩa của các mối quan hệ.
Trong đó:
-
Original Sample: Hệ số tác động chuẩn hóa ước lượng từ dữ liệu gốc (SMARTPLS không cung cấp hệ số chưa chuẩn hóa).
-
Sample Mean: Giá trị trung bình của hệ số tác động chuẩn hóa thu được từ các mẫu Bootstrap.
-
Standard Deviation: Độ lệch chuẩn của hệ số tác động chuẩn hóa dựa trên các mẫu Bootstrap.
-
T Statistics: Giá trị thống kê t dùng để kiểm định ý nghĩa của mối quan hệ.
-
P Values: Mức ý nghĩa thống kê của kiểm định t, được so sánh với các ngưỡng 0.05, 0.10 hoặc 0.01 (trong nghiên cứu này sử dụng ngưỡng 0.05).
.jpg)
Kết quả phân tích Bootstrap cho thấy tất cả các mối quan hệ trong mô hình đều có P Values = 0.000 < 0.05, do đó các mối tác động đều có ý nghĩa thống kê ở mức tin cậy 95%.
Cụ thể, có bốn biến tiềm ẩn tác động đến biến Sự hài lòng của khách hàng (HL) gồm BM, GC, HI và SD. Hệ số tác động chuẩn hóa của các biến này lần lượt là SD (0.401), HI (0.349), BM (0.326) và GC (0.317). Như vậy, xét theo mức độ ảnh hưởng từ mạnh đến yếu, các biến tác động đến HL được sắp xếp theo thứ tự: SD → HI → BM → GC.
Bên cạnh đó, biến HL có tác động trực tiếp đến biến Ý định tiếp tục mua sắm trực tuyến (YD) với hệ số tác động chuẩn hóa là 0.751, cho thấy mức độ ảnh hưởng mạnh và có ý nghĩa thống kê.
4.2 Đánh giá hiện tượng đa cộng tuyến
Để đánh giá đa cộng tuyến, chúng ta sẽ sử dụng kết quả của phân tích PLS Algorithm. Cách chạy phân tích PLS Algorithm bạn xem Đánh giá mô hình đo lường.
.jpg)
Để đánh giá hiện tượng đa cộng tuyến trong mô hình, chọn Collinearity Statistics (VIF) trong kết quả PLS Algorithm. Chỉ số VIF được trình bày dưới hai dạng gồm Inner VIF và Outer VIF.
Trong đó:
-
Inner VIF Values: Dùng để đánh giá hiện tượng đa cộng tuyến giữa các biến tiềm ẩn độc lập trong mô hình cấu trúc. Đây là chỉ số quan trọng nhất, vì đa cộng tuyến giữa các biến tiềm ẩn có thể ảnh hưởng nghiêm trọng đến kết quả ước lượng.
-
Outer VIF Values: Dùng để đánh giá đa cộng tuyến giữa các biến quan sát. Đối với các thang đo được xây dựng theo mô hình reflective, chỉ số này không cần xem xét.
.jpg)
Bảng kết quả VIF được trình bày dưới dạng ma trận, trong đó các hàng thể hiện biến phụ thuộc (mục số 2) và các cột thể hiện các biến độc lập (mục số 1) tác động vào từng biến phụ thuộc trong mô hình cấu trúc.
Kết quả cho thấy, trong mô hình SEM đang xét có hai biến phụ thuộc là HL và YD. Cụ thể, biến HL chịu tác động từ bốn biến độc lập gồm BM, GC, HI và SD, do đó tại cột HL xuất hiện bốn giá trị VIF tương ứng. Trong khi đó, biến YD chỉ chịu tác động từ một biến độc lập là HL, nên tại cột YD chỉ có một giá trị VIF.
Theo Hair và cộng sự (2019), nếu VIF từ 5 trở đi, mô hình có khả năng rất cao xuất hiện hiện tượng đa cộng tuyến. Ngưỡng đánh giá VIF do tác giả đề xuất:
| Giá trị VIF | Mức độ đa cộng tuyến |
|---|---|
| VIF ≥ 5 | Khả năng xuất hiện hiện tượng đa cộng tuyến là rất cao |
| 3 ≤ VIF < 5 | Có thể gặp hiện tượng đa cộng tuyến |
| VIF < 3 | Có thể không có hiện tượng đa cộng tuyến |
Kết quả phân tích cho thấy các giá trị Inner VIF trong mô hình đều nhỏ hơn 3, dao động từ 1.000 đến 1.079, đáp ứng ngưỡng khuyến nghị của Hair và cộng sự (2019). Do đó, mô hình nghiên cứu không xuất hiện hiện tượng đa cộng tuyến, và các mối quan hệ trong mô hình cấu trúc có thể được đánh giá một cách đáng tin cậy.
4.3 Đánh giá mức độ giải thích của mô hình SEM thông qua R²
Để xác định mức độ mà một hoặc nhiều biến độc lập giải thích cho biến phụ thuộc trong mô hình SEM, nghiên cứu sử dụng chỉ số R bình phương (R²) hoặc R bình phương hiệu chỉnh (Adjusted R²). Trong đó, R² hiệu chỉnh được ưu tiên sử dụng vì phản ánh chính xác hơn khả năng giải thích của mô hình, đặc biệt khi số lượng biến độc lập lớn.
.jpg)
Nhấp vào R Square để xem kết quả.
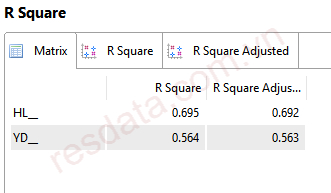
Dựa vào kết quả phân tích trong hình, mô hình nghiên cứu có hai biến phụ thuộc là HL và YD. Cụ thể, biến HL nhận tác động từ các biến độc lập trong mô hình và có giá trị R² hiệu chỉnh bằng 0.692. Điều này cho thấy các biến độc lập tác động vào HL đã giải thích được 69.2% sự biến thiên (phương sai) của biến HL, mức độ giải thích được đánh giá là khá cao trong nghiên cứu khoa học xã hội.
Trong khi đó, biến YD chịu tác động từ biến độc lập HL và có giá trị R² hiệu chỉnh bằng 0.563. Kết quả này cho thấy biến HL đã giải thích được 56.3% sự biến thiên của biến YD, thể hiện mức độ giải thích ở mức trung bình đến tốt.
Nhìn chung, giá trị R bình phương (cũng như R bình phương hiệu chỉnh) dao động trong khoảng từ 0 đến 1, trong đó giá trị càng tiến gần về 1 cho thấy khả năng giải thích của mô hình càng mạnh. Với các giá trị R² hiệu chỉnh thu được trong mô hình này, có thể kết luận rằng mô hình SEM có mức độ giải thích phù hợp và đáp ứng yêu cầu phân tích.
4.4 Đánh giá mức độ ảnh hưởng thông qua hệ số f²
Để đánh giá hệ số f² (effect size), chúng ta tiếp tục sử dụng kết quả phân tích PLS Algorithm trong SMARTPLS 3. Nhấp vào f Square để xem kết quả.
.jpg)
Bảng kết quả f bình phương (f²) được trình bày tương tự như bảng Inner VIF Values, trong đó mỗi giá trị f² phản ánh mức độ ảnh hưởng mạnh hay yếu của biến độc lập đối với biến phụ thuộc. Chỉ số này giúp đánh giá mức đóng góp riêng của từng biến độc lập trong mô hình.
Trong nhiều trường hợp, thứ tự mức độ ảnh hưởng theo hệ số tác động chuẩn hóa (cột Original Sample trong bảng Path Coefficients) trùng với thứ tự lớn – nhỏ của hệ số f². Do đó, cả hai chỉ số này đều có thể được sử dụng để so sánh mức độ tác động của các biến độc lập khi chúng cùng ảnh hưởng đến một biến phụ thuộc.
Cohen (1988) đã đề xuất bảng chỉ số f Square để đánh giá các biến độc lập như sau:
- f Square < 0.02: mức tác động cực kỳ nhỏ hoặc không có tác động.
- 0.02 ≤ f Square < 0.15: mức tác động nhỏ.
- 0.15 ≤ f Square < 0.35: mức tác động trung bình.
- f Square ≥ 0.35: mức tác động lớn.
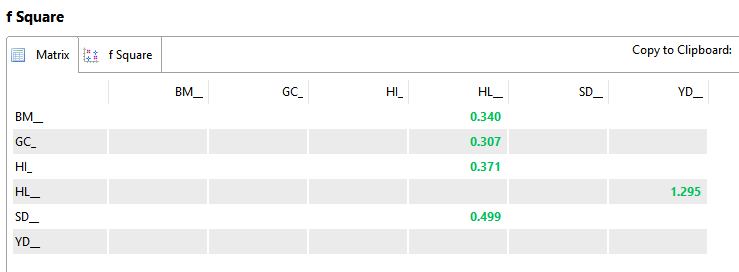
Dựa trên bảng kết quả f Square, mức độ ảnh hưởng của các biến độc lập lên biến phụ thuộc trong mô hình SEM không đồng đều, cụ thể:
-
BM → HL có f² = 0.340, cho thấy mức độ ảnh hưởng trung bình, tiệm cận mức ảnh hưởng mạnh.
-
GC → HL có f² = 0.307, thể hiện mức độ ảnh hưởng trung bình.
-
HI → HL có f² = 0.371, cho thấy mức độ ảnh hưởng mạnh lên biến HL.
-
SD → HL có f² = 0.499, phản ánh mức độ ảnh hưởng mạnh.
-
HL → YD có f² = 1.295, cho thấy mức độ ảnh hưởng rất mạnh của HL đối với YD.
Theo ngưỡng đánh giá của Hair và cộng sự, các kết quả trên cho thấy đa số các biến độc lập có ảnh hưởng từ trung bình đến mạnh, trong đó mối quan hệ HL → YD là mối quan hệ có tác động mạnh nhất trong mô hình.
5. Các lỗi thường gặp khi đánh giá mô hình cấu trúc SEM
Nhầm lẫn giữa đánh giá mô hình đo lường và mô hình cấu trúc
Nhiều người trình bày Cronbach’s Alpha, AVE, HTMT trong phần mô hình cấu trúc. Đây là lỗi phổ biến. Các chỉ số này chỉ dùng cho mô hình đo lường, không dùng để kết luận mô hình cấu trúc.
Chỉ nhìn vào hệ số đường dẫn mà bỏ qua ý nghĩa thống kê
Một hệ số tác động lớn nhưng không có ý nghĩa thống kê (p-value > 0.05) thì không được chấp nhận giả thuyết. Luôn phải xem đồng thời Original Sample, T-value và P-value.
Không kiểm tra đa cộng tuyến trước khi kết luận mô hình
Việc bỏ qua Inner VIF Values có thể dẫn đến kết luận sai về mức độ tác động của các biến. Nếu VIF ≥ 5, mô hình có nguy cơ cao bị đa cộng tuyến và kết quả hồi quy không còn đáng tin cậy.
Kết luận f² dựa trên cảm tính
Một số nghiên cứu chỉ so sánh độ lớn f² giữa các biến mà không đối chiếu ngưỡng đánh giá chuẩn, dẫn đến kết luận sai rằng biến có ảnh hưởng mạnh trong khi thực tế chỉ ở mức trung bình hoặc yếu.
Sử dụng R² nhưng không giải thích ý nghĩa thực tiễn
R² không chỉ để “báo cáo con số”. Người nghiên cứu cần diễn giải ý nghĩa mức độ giải thích của mô hình đối với bối cảnh nghiên cứu cụ thể (hành vi, sự hài lòng, ý định,…).
6. Kết luận
Bài viết đã trình bày toàn bộ quy trình đánh giá mô hình cấu trúc SEM trên SMARTPLS 3 một cách hệ thống, từ bước chạy Bootstrapping đến việc diễn giải các chỉ số quan trọng trong mô hình nghiên cứu. Thông qua kết quả phân tích, có thể khẳng định rằng mô hình SEM được xây dựng đáp ứng đầy đủ các yêu cầu đánh giá tiêu chuẩn trong nghiên cứu định lượng.
Cụ thể, kết quả Inner VIF cho thấy mô hình không tồn tại hiện tượng đa cộng tuyến, đảm bảo độ tin cậy của các ước lượng hồi quy. Các hệ số đường dẫn đều có ý nghĩa thống kê, chứng minh rằng các giả thuyết nghiên cứu được dữ liệu thực nghiệm ủng hộ. Bên cạnh đó, các giá trị R² hiệu chỉnh cho thấy mô hình có khả năng giải thích từ trung bình đến cao đối với các biến phụ thuộc, trong khi hệ số f² phản ánh mức độ ảnh hưởng từ trung bình đến mạnh của các biến độc lập, đặc biệt là mối quan hệ HL → YD có tác động rất mạnh.
Tổng hợp các kết quả trên, có thể kết luận rằng mô hình cấu trúc SEM trên SMARTPLS 3 được đánh giá là phù hợp, có ý nghĩa thống kê và có giá trị thực tiễn, đáp ứng tốt yêu cầu của các đề tài nghiên cứu và luận văn trong lĩnh vực khoa học xã hội và quản trị. Việc thực hiện đúng quy trình đánh giá mô hình cấu trúc không chỉ giúp nâng cao chất lượng nghiên cứu mà còn giúp người học tự tin hơn khi bảo vệ luận văn và công bố kết quả nghiên cứu.
Tham khảo:
Hair et al. (2016), A Primer on Partial Least Squares Structural Equation Modeling (PLS-SEM), Second Edition, Sage Publications, New York.
-------------------
Nội dung được Resdata biên soạn dựa trên kinh nghiệm trực tiếp trong quá trình xử lý và phân tích dữ liệu cho nhiều đề tài nghiên cứu khác nhau. Trong trường hợp bạn gặp khó khăn khi thao tác SPSS, chưa tự tin trong việc đọc và diễn giải kết quả, hoặc cần hỗ trợ để hoàn thiện mô hình nghiên cứu đúng hướng và đúng chuẩn học thuật, dịch vụ cài đặt SmartPLS của ResData sẵn sàng đồng hành và hỗ trợ bạn giúp bạn vượt qua mọi deadline cận kề nhất.






