Kiểm định Anova trong SPSS
Kiểm định ANOVA (Analysis of Variance) là phương pháp thống kê dùng để so sánh trung bình của 3 nhóm trở lên nhằm xác định xem có khác biệt đáng kể giữa các nhóm hay không trong dữ liệu SPSS. Đây là một trong những kỹ thuật phân tích rất phổ biến trong nghiên cứu khoa học, đặc biệt khi bạn muốn kiểm tra ảnh hưởng của một biến định tính (có ≥3 mức) lên một biến định lượng.
1. ANOVA là gì? Dùng trong trường hợp nào?
ANOVA (Analysis of Variance) là phép kiểm định thống kê giúp người nghiên cứu đánh giá xem có sự khác biệt đáng kể về giá trị trung bình của một biến liên tục giữa nhiều hơn hai nhóm phân loại hay không.
Ví dụ: Bạn muốn biết mức độ hài lòng khác nhau giữa khách hàng ở nhiều mức độ thu nhập khác nhau có khác biệt thực sự không? Hoặc điểm trung bình môn học có khác giữa sinh viên của 3 ngành khác nhau hay không? ANOVA là phương pháp phù hợp để trả lời các câu hỏi này.
ANOVA khác với t-test ở chỗ:
-
T-test so sánh hai nhóm
-
ANOVA so sánh 3 nhóm trở lên
2. Vai trò của ANOVA trong quy trình nghiên cứu
Kiểm định ANOVA đóng vai trò trọng tâm trong phân tích biến định lượng theo nhóm phân loại, bởi vì:
Giúp kiểm tra mức độ khác biệt trung bình giữa nhiều hơn hai nhóm cùng một lúc mà không bị lỗi loại I do so sánh từng cặp riêng lẻ.
Là bước phân tích bắt buộc khi bài nghiên cứu có biến phân loại (ví dụ: giới tính, nhóm tuổi, trình độ học vấn) và biến phụ thuộc là liên tục.
Là tiền đề để tiến tới các phân tích sâu hơn, ví dụ:
-
Post hoc để xác định nhóm nào khác biệt cụ thể
-
Phân tích hồi quy đa biến
-
Mô hình hóa nâng cao (ANOVA nhiều yếu tố, ANCOVA, MANOVA)
Nếu bỏ qua ANOVA trong nghiên cứu có từ 3 nhóm trở lên, bạn sẽ:
-
Dễ đưa ra kết luận sai lầm về khác biệt nhóm
-
Không biết được nhóm nào thực sự khác nhau
-
Làm giảm sức thuyết phục của luận văn/báo cáo
3. Phân loại kiểm định ANOVA trong SPSS
Trong thực hành SPSS, kiểm định ANOVA không chỉ có một dạng duy nhất mà được chia thành nhiều loại khác nhau, tùy theo số lượng biến độc lập, cách đo lường biến phụ thuộc và thiết kế nghiên cứu. Việc lựa chọn đúng loại ANOVA giúp kết quả phân tích chính xác và phù hợp với mục tiêu nghiên cứu.
One-Way ANOVA (ANOVA một yếu tố) được sử dụng khi nghiên cứu có một biến độc lập dạng phân loại với từ ba nhóm trở lên và một biến phụ thuộc liên tục. Đây là dạng ANOVA phổ biến nhất trong các nghiên cứu xã hội, kinh tế và marketing.
Two-Way ANOVA (ANOVA hai yếu tố) được dùng khi mô hình có hai biến độc lập, cho phép đánh giá ảnh hưởng riêng của từng biến cũng như tác động tương tác giữa chúng lên biến phụ thuộc.
Repeated Measures ANOVA (ANOVA đo lặp) áp dụng khi biến phụ thuộc được đo nhiều lần trên cùng một đối tượng, thường gặp trong các nghiên cứu trước – sau hoặc nghiên cứu theo thời gian.
ANCOVA là dạng ANOVA có thêm biến hiệp biến nhằm kiểm soát các yếu tố gây nhiễu, giúp kết quả so sánh giữa các nhóm chính xác hơn.
MANOVA được sử dụng khi nghiên cứu có nhiều biến phụ thuộc liên tục, cho phép đánh giá đồng thời ảnh hưởng của biến độc lập lên nhiều kết quả khác nhau.
4. Điều kiện để thực hiện ANOVA trong SPSS
Để ANOVA cho kết quả hợp lệ và tin cậy, dữ liệu cần đáp ứng các điều kiện sau:
Dạng dữ liệu
-
Biến phụ thuộc phải là biến liên tục (điểm số, mức độ, thu nhập, thời gian…)
-
Biến độc lập phải là biến phân loại với 3 nhóm trở lên
Phân phối chuẩn
-
Dữ liệu trong mỗi nhóm cần phân phối gần chuẩn
-
Nếu phân phối lệch mạnh, có thể cân nhắc biến đổi dữ liệu hoặc dùng kiểm định không tham số như Kruskal-Wallis
Độ đồng nhất phương sai
-
Phương sai giữa các nhóm cần tương đối giống nhau
-
Kiểm tra bằng Levene’s Test trong SPSS
Cỡ mẫu
-
Cỡ mẫu trong mỗi nhóm nên đủ lớn để đảm bảo tính ổn định
-
Mẫu quá nhỏ có thể làm giảm độ tin cậy thống kê
5. Tiêu chuẩn đánh giá kết quả ANOVA
Khi đọc kết quả ANOVA trong SPSS, cần chú ý các chỉ số chính:
(1) Sig. của kiểm định ANOVA: là tiêu chuẩn quan trọng nhất để đưa ra kết luận tổng quát.
-
Sig. < 0.05 → Có sự khác biệt trung bình giữa ít nhất hai nhóm
-
Sig. ≥ 0.05 → Không có khác biệt đáng kể giữa các nhóm
(2) Kiểm định Levene (đồng nhất phương sai)
-
Sig. > 0.05 → phương sai giữa các nhóm là đồng nhất
-
Sig. ≤ 0.05 → phương sai không đồng nhất → cần dùng ANOVA không đối xứng (Welch)
(3) Post Hoc (nếu ANOVA có ý nghĩa)
Nếu ANOVA cho Sig. < 0.05, bước tiếp theo là:
-
Post Hoc test: xác định nhóm nào khác biệt với nhóm nào
-
Các lựa chọn phổ biến trong SPSS: Tukey, Bonferroni, Scheffé, LSD
6. Hướng dẫn chạy ANOVA trong SPSS
Để chạy trong SPSS 27, chúng ta vào Analyze → Compare Means → One-way ANOVA

Khi hộp thoại One-way ANOVA được mở ra. Thao tác chuyển biến GC1 vào ô biến phụ thuộc (Dependent List) và biến DOTUOI vào ô nhân tố tác động (Factor) bằng cách kéo thả và sử dụng mũi tên ở giữa.
.jpg)
Nhấn vào nút Post Hoc ở bên phải và tick chọn Tukey. Sau đó nhấn tiếp Continue.

Quay về hộp thoại ANOVA, chọn tiếp Options, tick vào ô Descriptive trong miền Statistic, sau đó nhấn Continue

Sau khi nhấp Continue, SPSS sẽ quay về giao diện ban đầu, các bạn nhấp chuột vào OK để xuất kết quả ra.
.jpg)
7. Phân tích kết quả và nhận xét
Quy trình chuẩn đọc kết quả ANOVA trên SPSS
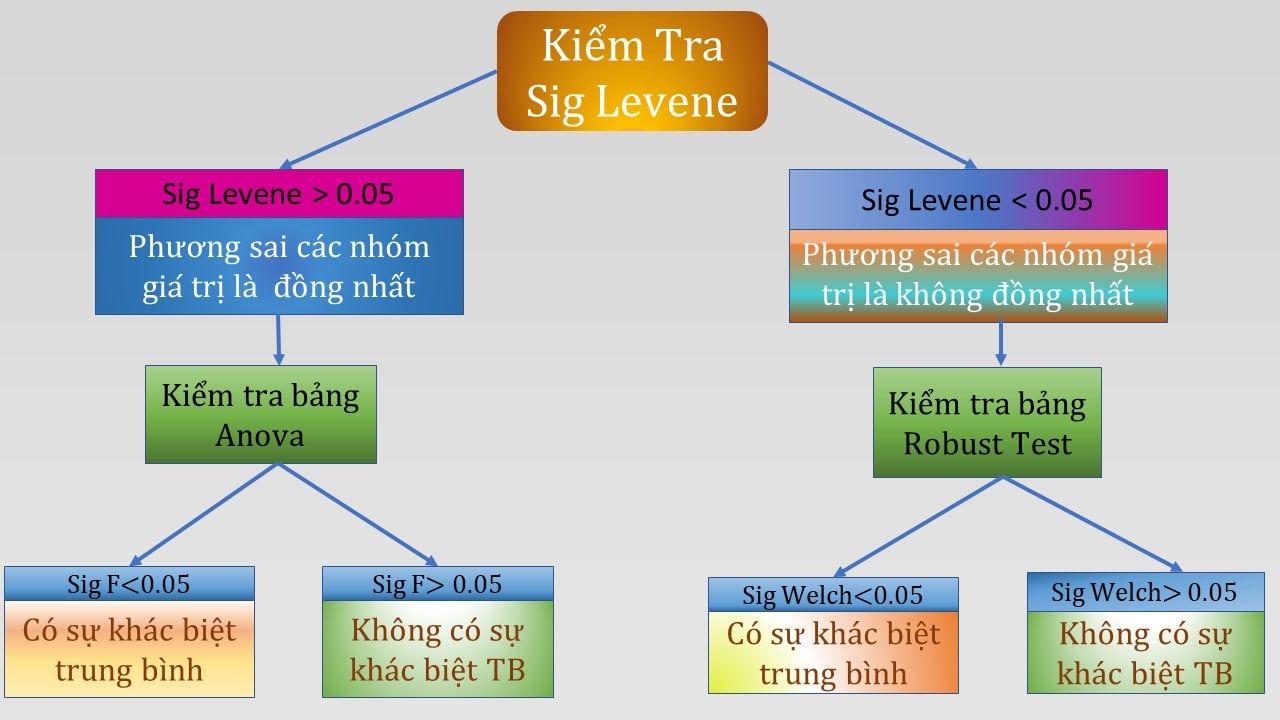
Bước 1: Xem Sig Homotest (Levene)
- Sig < 0,05 → phương sai không đồng nhất → không dùng ANOVA, chuyển sang Robust test (Welch)
- Sig > 0,05 → phương sai đồng nhất → dùng ANOVA
Bước 2: Xem Sig ANOVA hoặc Sig Robust
-
Sig < 0,05 → tồn tại sự khác biệt
-
Sig > 0,05 → không tồn tại sự khác biệt.
-
Ví dụ minh họa đọc kết quả dữ liệu Mức độ hài lòng khi sử dụng dịch vụ ngân hàng MB
| Đặc điểm nhân khẩu học | Sig Homotest | Sig ANOVA | Sig Robust test | Giải thích theo quy trình kiểm định | Kết luận |
|---|---|---|---|---|---|
| Thu nhập | 0,001 < 0,05 | – | 0,018 < 0,05 | Phương sai không đồng nhất → sử dụng kiểm định Robust (Welch); Sig Welch < 0,05 | Tồn tại sự khác biệt |
| Trình độ học vấn | 0,010 < 0,05 | – | 0,041 < 0,05 | Phương sai không đồng nhất → sử dụng kiểm định Robust (Welch); Sig Welch < 0,05 | Tồn tại sự khác biệt |
| Nghề nghiệp | 0,075 > 0,05 | 0,086 > 0,05 | – | Phương sai đồng nhất → sử dụng ANOVA; Sig ANOVA > 0,05 | Không tồn tại sự khác biệt |
| Thời gian sử dụng (TGSD) | 0,856 > 0,05 | 0,193 > 0,05 | – | Phương sai đồng nhất → sử dụng ANOVA; Sig ANOVA > 0,05 | Không tồn tại sự khác biệt |
7.1 Bảng mô tả (Descriptives)
.jpg)
Kết quả:
-
Dưới 5 triệu: Mean = 3.4519 (N=52)
-
5 - dưới 10 triệu: Mean = 3.4000 (N=60)
-
10 - 20 triệu: Mean = 4.1281 (N=80)
-
Trên 20 triệu: Mean = 4.2500 (N=8)
-
Tổng thể (Total): Mean = 3.7388 (N=200)
Nhận xét:
-
Có sự chênh lệch về điểm đánh giá trung bình (Mean) giữa các nhóm thu nhập.
-
Nhóm thu nhập cao (10-20 triệu và Trên 20 triệu) có điểm đánh giá HL cao hơn hẳn (đều trên 4.0) so với hai nhóm thu nhập thấp (chỉ khoảng 3.4).
-
Lưu ý: Nhóm "Trên 20 triệu" có kích thước mẫu khá nhỏ (N=8) so với các nhóm khác, điều này có thể ảnh hưởng đến độ chính xác của ước lượng (độ lệch chuẩn/Std. Deviation của nhóm này thấp nhất 0.46, nhưng khoảng tin cậy lại khá rộng do mẫu nhỏ).
7.2 Bảng ANOVA
(1).jpg)
Kết quả:
-
Giá trị F = 12.466
-
Mức ý nghĩa Sig. < 0.001
Nhận xét:
-
Vì giá trị Sig. = 0.001 < 0.05, Tồn tại sự khác biệt
-
Kết luận: Có sự khác biệt có ý nghĩa thống kê về mức độ Hài Lòng (HL) giữa các nhóm thu nhập khác nhau. Nói cách khác, Thu nhập khác nhau sẽ dẫn đến sự đánh giá HL khác nhau.
7.3 Bảng Multiple Comparisons
.jpg)
Sau khi biết "có sự khác biệt" từ bảng ANOVA, ta dùng bảng này (Tukey HSD) để biết chính xác nhóm nào khác nhóm nào.
Kết quả từ kiểm định Tukey HSD:
-
Nhóm "Dưới 5 triệu" so với các nhóm khác:
-
Khác biệt với nhóm "10-20 triệu" (Sig. < 0.001): Nhóm 10-20 triệu hài lòng cao hơn.
-
Không khác biệt với nhóm "5-dưới 10 triệu" (Sig. = 0.987).
-
Không khác biệt rõ rệt với nhóm "Trên 20 triệu" theo chuẩn Tukey (Sig. = 0.055 > 0.05). Tuy nhiên, giá trị này rất sát mức 0.05 và ở kiểm định LSD lỏng hơn thì nó có khác biệt. Do mẫu nhóm trên 20tr quá nhỏ nên kiểm định Tukey khó phát hiện sự khác biệt.
-
-
Nhóm "5 - dưới 10 triệu" so với các nhóm khác:
-
Khác biệt với nhóm "10-20 triệu" (Sig. < 0.001): Nhóm 10-20 triệu hài lòng cao hơn.
-
Khác biệt với nhóm "Trên 20 triệu" (Sig. = 0.034): Nhóm Trên 20 triệu hài lòng cao hơn.
-
-
Nhóm "10 - 20 triệu" so với "Trên 20 triệu":
-
Không có sự khác biệt (Sig. = 0.978).
-
Nhận xét: Dữ liệu đang chia thành 2 phân khúc rõ rệt về sự hài lòng:
-
Phân khúc 1 (Thu nhập thấp < 10 triệu): Gồm nhóm "Dưới 5 triệu" và "5-10 triệu". Hai nhóm này có mức độ hài lòng thấp tương đương nhau (khoảng 3.4).
-
Phân khúc 2 (Thu nhập cao > 10 triệu): Gồm nhóm "10-20 triệu" và "Trên 20 triệu". Hai nhóm này có mức độ hài lòng cao tương đương nhau (khoảng 4.1 - 4.2).
Sự khác biệt ý nghĩa nhất nằm giữa Phân khúc 1 và Phân khúc 2. Người có thu nhập trên 10 triệu có xu hướng Hài lòng cao hơn hẳn người có thu nhập dưới 10 triệu.
8. Kết Luận
Bài viết trình bày một cách toàn diện về kiểm định ANOVA trong SPSS, bao gồm khái niệm, mục đích, các loại phân tích (như One-Way, Two-Way và MANOVA), điều kiện áp dụng và từng bước thực hành trong phần mềm. Nội dung nhấn mạnh kiểm định ANOVA là kỹ thuật thống kê để so sánh sự khác biệt về giá trị trung bình giữa hai nhóm trở lên, giúp đánh giá ảnh hưởng của biến độc lập lên biến phụ thuộc và mở rộng hơn so với kiểm định t-test truyền thống. Bài cũng hướng dẫn cách thiết lập và chạy lệnh ANOVA trong SPSS, cách kiểm tra giả định như đồng nhất phương sai và cách đọc các bảng kết quả đầu ra để diễn giải ý nghĩa thống kê. Khi thực hiện đúng quy trình kiểm định ANOVA, người nghiên cứu có thể xác định được sự khác biệt có ý nghĩa thống kê giữa các nhóm nghiên cứu, từ đó rút ra kết luận chính xác cho mô hình nghiên cứu của mình.
Hy vọng qua bài hướng dẫn chi tiết trên, bạn đã nắm vững quy trình thực hiện kiểm định ANOVA. Tuy nhiên, trong thực tế xử lý số liệu, bạn có thể gặp phải các vấn đề phức tạp như dữ liệu không chuẩn, phương sai không đồng nhất hay vi phạm các giả định thống kê.
Để hạn chế sai sót trong quá trình xử lý dữ liệu và đảm bảo kết quả phân tích phản ánh đúng bản chất nghiên cứu, bạn nên tham khảo thêm bài viết tổng hợp những điều cần lưu ý khi chạy SPSS cho kết quả tốt , trong đó trình bày toàn diện các vấn đề quan trọng từ chuẩn bị dữ liệu, kiểm định thang đo đến phân tích và diễn giải kết quả.
------------------------
Resdata hỗ trợ bạn những gì?
✅ Tư vấn & định hướng toàn bộ quy trình xử lý dữ liệu SPSS: Rà soát thang đo, phát hiện và xử lý các biến không phù hợp, đồng thời định hướng từng bước phân tích (Cronbach’s Alpha, EFA, hồi quy/SEM…) theo đúng bản chất dữ liệu, bối cảnh nghiên cứu và mục tiêu đề tài, giúp kết quả phản ánh thực tế nghiên cứu và đáp ứng yêu cầu học thuật.
✅ Hỗ trợ SPSS 1 kèm 1 qua ultraview: Hướng dẫn chi tiết từng bước thực hành và cách viết nhận xét chuẩn học thuật.
✅ Xử lý nhanh – đúng chuẩn: Xử lý kết quả trong ngày. Phù hợp cho khóa luận, luận văn, luận án và bài báo khoa học.
✅ Cam kết chỉnh sửa theo góp ý của giảng viên/hội đồng cho đến khi đạt yêu cầu.
Nếu bạn đang gặp phải các tình huống trên và chưa tìm được hướng xử lý phù hợp, đừng ngần ngại liên hệ ngay: Hotline: 0907 786 895.
Resdata luôn sẵn sàng đồng hành cùng bạn với phương châm: Nhanh chóng – Tin cậy – Bảo mật – Chi phí hợp lý.






