Hồi quy nhị phân trong SPSS
Hồi quy nhị phân (Binary Logistic Regression) trong SPSS là phương pháp phân tích giúp xác định xác suất xảy ra của một sự kiện có hai trạng thái dựa trên các yếu tố tác động. Bài viết này hướng dẫn chi tiết từ điều kiện áp dụng, tiêu chuẩn đánh giá, cách thao tác trên SPSS đến cách đọc và viết kết quả hồi quy nhị phân đúng chuẩn luận văn và nghiên cứu khoa học.
1. Hồi quy nhị phân (Binary Logistic Regression) là gì? Dùng trong trường hợp nào?
Hồi quy nhị phân (Binary Logistic Regression) là phương pháp phân tích thống kê dùng để xác định mối quan hệ giữa một biến phụ thuộc có hai trạng thái và một hoặc nhiều biến độc lập, từ đó ước lượng xác suất xảy ra của một sự kiện cụ thể. Phương pháp này đặc biệt phù hợp khi biến kết quả không đo lường bằng giá trị liên tục mà chỉ phản ánh hai khả năng rõ ràng như có/không, đồng ý/không đồng ý, thành công/thất bại.
Trong thực tế nghiên cứu, hồi quy nhị phân thường được sử dụng để trả lời các câu hỏi dạng: yếu tố nào làm tăng khả năng mua hàng của khách hàng, nhân tố nào ảnh hưởng đến khả năng sinh viên đạt chuẩn đầu ra, hoặc khả năng người lao động nghỉ việc phụ thuộc vào những yếu tố nào. Trong các trường hợp này, nếu sử dụng hồi quy tuyến tính thông thường sẽ dẫn đến sai lệch kết quả, do đó hồi quy nhị phân là lựa chọn phù hợp và chính xác hơn.
2. Vai trò của hồi quy nhị phân trong quy trình nghiên cứu
Trong quy trình nghiên cứu định lượng, hồi quy nhị phân thường được thực hiện sau khi hoàn tất các bước kiểm định thang đo và phân tích nhân tố nhằm đảm bảo các biến đưa vào mô hình là hợp lệ và có ý nghĩa. Phương pháp này giúp người nghiên cứu không chỉ kiểm tra mối quan hệ giữa các biến mà còn dự đoán xác suất xảy ra của biến phụ thuộc, điều mà các phép kiểm so sánh trung bình không thực hiện được.
Nếu bỏ qua hồi quy nhị phân khi biến phụ thuộc là biến nhị phân, kết quả nghiên cứu có thể thiếu cơ sở khoa học và khó thuyết phục. Ngược lại, kết quả hồi quy nhị phân là tiền đề quan trọng để thảo luận kết quả nghiên cứu, xây dựng hàm ý quản trị và đưa ra các khuyến nghị mang tính thực tiễn.
3. Điều kiện để thực hiện hồi quy nhị phân trong SPSS
Để hồi quy nhị phân được áp dụng đúng, dữ liệu cần đáp ứng các điều kiện sau:
-
Biến phụ thuộc phải là biến nhị phân, chỉ có hai giá trị và được mã hóa rõ ràng (thường là 0 và 1).
-
Biến độc lập có thể là biến định lượng, biến định tính đã mã hóa hoặc biến đo lường theo thang Likert.
-
Cỡ mẫu đủ lớn, thông thường tối thiểu 10–15 quan sát cho mỗi biến độc lập trong mô hình.
-
Các quan sát độc lập với nhau, không có hiện tượng trùng lặp dữ liệu.
-
Không tồn tại đa cộng tuyến nghiêm trọng giữa các biến độc lập.
-
Không yêu cầu biến độc lập phải phân phối chuẩn, đây là ưu điểm lớn của hồi quy nhị phân so với hồi quy tuyến tính.
4. Các tiêu chuẩn đánh giá kết quả hồi quy nhị phân
Bảng dưới đây là bảng tra cứu nhanh các tiêu chuẩn đánh giá hồi quy nhị phân trong SPSS, rất phù hợp để sử dụng trong luận văn và bài viết hướng dẫn.
| Tiêu chí | Bảng SPSS | Yêu cầu | Ý nghĩa |
|---|---|---|---|
| Độ phù hợp tổng thể của mô hình | Omnibus Tests of Model Coefficients | Sig. < 0.05 | Mô hình phù hợp với dữ liệu; các biến độc lập có tác động tổng thể đến biến phụ thuộc |
| Mức cải thiện mô hình | Model Summary | −2 Log Likelihood giảm | −2LL càng nhỏ chứng tỏ mô hình dự đoán tốt hơn so với mô hình rỗng |
| Độ phù hợp với dữ liệu quan sát | Hosmer and Lemeshow Test | Sig. > 0.05 | Không có sự khác biệt đáng kể giữa giá trị dự đoán và giá trị thực tế |
| Ý nghĩa thống kê của biến | Variables in the Equation | Sig. < 0.05 | Biến độc lập có ảnh hưởng có ý nghĩa thống kê đến biến phụ thuộc |
| Mức độ tác động của biến | Variables in the Equation | Exp(B) ≠ 1 | Exp(B) > 1 làm tăng xác suất xảy ra; Exp(B) < 1 làm giảm xác suất xảy ra |
| Đa cộng tuyến (khuyến nghị) | Hồi quy tuyến tính phụ trợ | VIF < 5 | Không tồn tại đa cộng tuyến nghiêm trọng, mô hình ổn định |
5. Hướng dẫn thực hiện hồi quy nhị phân trong SPSS
Trong bộ dữ liệu khảo sát tại hệ thống siêu thị, chúng ta muốn tìm hiểu các yếu tố nhân khẩu học và hành vi tác động như thế nào đến Quyết định (QD) của khách hàng. Cụ thể, Ban quản lý siêu thị muốn biết liệu thu nhập, độ tuổi hay tần suất đi mua sắm có ảnh hưởng đến việc khách hàng quyết định "Gắn bó/Quay lại" (hoặc hài lòng) với siêu thị hay không.
Mô hình hồi quy nhị phân được thiết lập với các biến như sau:
Biến phụ thuộc (Dependent Variable): QD (Quyết định).
-
Giá trị 0: Không chọn/Không quay lại.
-
Giá trị 1: Có chọn/Có quay lại.
Biến độc lập (Covariates):
-
SP
-
GC
-
TB
-
NV
-
DD
-
XT
Thực hiện hồi quy nhị phân trên phần mềm SPSS. Chúng ta vào Analyze > Regression > Binary Logistic…
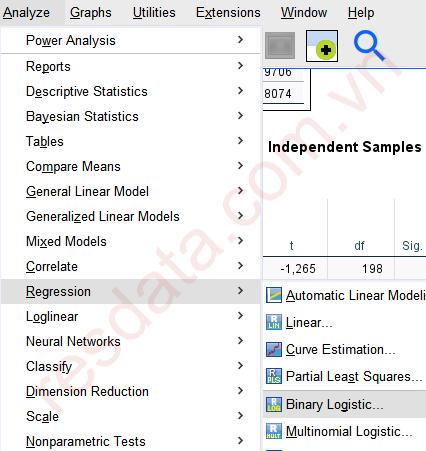
Đưa biến phụ thuộc QD vào mục Dependent, đưa các biến độc lập vào mục Covariates. Sau đó tại mục Method, chọn phương pháp Enter. Tiếp tục nhấp vào OK để xuất các bảng kết quả.
.png)
Vào Options, tích chọn Classification plots, Hosmer-Lemeshow goodness-of-fit, CI for exp(B), Iteration history. Nhấn OK.
.jpg)
6. Kết quả và nhận xét
Bảng Case Processing Summary cho chúng ta các thông tin mô tả đặc điểm dữ liệu đưa vào phân tích hồi quy nhị phân. Cụ thể ở đây, có 300 quan sát (cỡ mẫu hợp lệ) được đưa vào phân tích (Included in Analysis), không có quan sát nào bị thiếu số liệu (Missing Cases), không có quan sát nào không được chọn (Unselected Cases).
.jpg)
Bảng Dependent Variable Encoding cho biết biến phụ thuộc đang mang 2 giá trị, "Không được lựa chọn" mã hóa là 0 và "Lựa chọn siêu thị để mua sắm" mã hóa là 1.
.jpg)
Phần tiếp theo là kết quả ở Block 0. Chúng ta sẽ bỏ qua phần này bởi vì các kết quả phân tích ở Block 0 nằm ở trường hợp không có bất kỳ biến độc lập nào được đưa vào mô hình. Chúng ta sẽ đọc kết quả phân tích ở Block 1.
Bảng đầu tiên là Omnibus Tests of Model Coefficients. Bảng này cho kết quả phân tích các hệ số của mô hình. Step 1 là bước thứ nhất trong chạy mô hình Logistic. Do ở đây chúng ta dùng phương pháp Enter đưa các biến độc lập vào cùng một lần nên chỉ xuất hiện Step 1 trong kết quả thống kê. Trường hợp dùng các phương pháp khác bảng này sẽ có thêm các Step 2, 3, 4 tùy số lượng biến đưa vào
.jpg)
Cột Chi-square và Sig. thể hiện kết quả của kiểm định Chi bình phương, đây là kiểm định để đánh giá giả thuyết sự phù hợp của mô hình hồi quy. Giá trị sig kiểm định Chi-square ở hàng Model bằng 0.001 < 0.05, do đó, mô hình hồi quy là phù hợp.
Bảng tiếp theo là Model Summary cho kết quả mức độ phù hợp của mô hình.
.jpg)
Kết quả bảng Model Summary cho thấy mô hình hồi quy nhị phân có giá trị –2 Log Likelihood đạt 121.728 và hội tụ sau 8 vòng lặp. Chỉ số Nagelkerke R Square đạt 0.764, cho thấy các biến độc lập trong mô hình giải thích được khoảng 76.4% sự biến thiên của biến phụ thuộc. Điều này chứng tỏ mô hình có mức độ phù hợp rất tốt và đủ điều kiện để tiếp tục phân tích các biến ảnh hưởng trong bảng Variables in the Equation.
Bảng thứ ba là Classification Table cho thấy phân loại đối tượng không được lựa chọn và lựa chọn siêu thị để mua sắm theo hai tiêu chí: quan sát thực tế và dự đoán.
.jpg)
- Trong 77 trường hợp quan sát không lựa chọn, thì dự đoán có 61 trường hợp không chọn, tỉ lệ dự đoán đúng là 79,2%
- Trong 223 trường hợp quan sát lựa chọn, dự đoán có 214 trường hợp lựa chọn, tỉ lệ dự đoán đúng là 96%
Như vậy, tỷ lệ trung bình dự đoán đúng là 91,7%
Bảng thứ 4 là Hosmer and Lemeshow Test cho biết mức độ phù hợp của mô hình với dữ liệu thực tế.
.jpg)
Kết quả phân tích cho thấy giá trị kiểm định Chi-square = 16,187 với mức ý nghĩa Sig. = 0,040.
Do giá trị Sig. = 0,04 < 0,05. Điều này chứng tỏ có sự khác biệt có ý nghĩa thống kê giữa giá trị dự báo của mô hình và giá trị quan sát thực tế.
Bảng cuối cùng là Variables in the Equation cho chúng ta kết quả kiểm định Wald, hệ số hồi quy và Exp(B) từng biến độc lập.
.jpg)
Kết quả bảng Variables in the Equation cho thấy tất cả các biến độc lập trong mô hình đều có ý nghĩa thống kê với Sig. < 0.05. Trong đó, biến GC có mức ảnh hưởng mạnh nhất với Exp(B) = 7.033, tiếp theo là SP và NV. Các biến đều tác động cùng chiều đến biến phụ thuộc, cho thấy khi các yếu tố này gia tăng sẽ làm tăng xác suất xảy ra của biến phụ thuộc trong mô hình hồi quy nhị phân.
Để hạn chế sai sót trong quá trình xử lý dữ liệu và đảm bảo kết quả phân tích phản ánh đúng bản chất nghiên cứu, bạn nên tham khảo thêm bài viết tổng hợp những điều cần lưu ý khi chạy SPSS cho kết quả tốt , trong đó trình bày toàn diện các vấn đề quan trọng từ chuẩn bị dữ liệu, kiểm định thang đo đến phân tích và diễn giải kết quả.
------------------------
Resdata hỗ trợ bạn những gì?
✅ Tư vấn & định hướng toàn bộ quy trình xử lý dữ liệu SPSS: Rà soát thang đo, phát hiện và xử lý các biến không phù hợp, đồng thời định hướng từng bước phân tích (Cronbach’s Alpha, EFA, hồi quy/SEM…) theo đúng bản chất dữ liệu, bối cảnh nghiên cứu và mục tiêu đề tài, giúp kết quả phản ánh thực tế nghiên cứu và đáp ứng yêu cầu học thuật.
✅ Hỗ trợ SPSS 1 kèm 1 qua ultraview: Hướng dẫn chi tiết từng bước thực hành và cách viết nhận xét chuẩn học thuật.
✅ Xử lý nhanh – đúng chuẩn: Xử lý kết quả trong ngày. Phù hợp cho khóa luận, luận văn, luận án và bài báo khoa học.
✅ Cam kết chỉnh sửa theo góp ý của giảng viên/hội đồng cho đến khi đạt yêu cầu.
Nếu bạn đang gặp phải các tình huống trên và chưa tìm được hướng xử lý phù hợp, đừng ngần ngại liên hệ ngay: Hotline: 0907 786 895.
Resdata luôn sẵn sàng đồng hành cùng bạn với phương châm: Nhanh chóng – Tin cậy – Bảo mật – Chi phí hợp lý.






