Thống kê mô tả trong SPSS: Khi nào dùng tần số, khi nào dùng giá trị trung bình
Trong bài viết trước về chủ đề Thống kê tần số và vẽ biểu đồ, Resdata đã cùng các bạn tìm hiểu quy trình lập bảng tần số cũng như trực quan hóa dữ liệu. Tuy nhiên, phương pháp này chỉ thực sự phát huy hiệu quả tối đa đối với các biến định tính/phân loại như Giới tính, Độ tuổi hay Nghề nghiệp.
Ngược lại, đối với các biến định lượng điển hình là các câu hỏi sử dụng thang đo Likert các múc độ (1 đến 5; 1-7 hoặc 1 đến 9) thường gặp trong nghiên cứu kinh tế xã hội, việc chỉ dừng lại ở tính toán tỷ lệ phần trăm (%) là chưa đủ và không phản ánh được toàn diện bản chất của dữ liệu. Chính vì vậy, chúng ta bắt buộc phải chuyển sang sử dụng công cụ Thống kê mô tả GIÁ TRỊ TRUNG BÌNH để tính toán các tham số đặc trưng như giá trị trung bình (Mean) hay độ lệch chuẩn. Trong bài viết này, Resdata sẽ đi sâu hướng dẫn các bạn quy trình thực hiện cũng như cách diễn giải kết quả kiểm định này trên phần mềm SPSS.
1. Mục đích sử dụng thống kê trung bình
Phân tích thống kê mô tả giữ vai trò nền tảng trong nghiên cứu định lượng, mang lại ba giá trị cốt lõi cho quá trình phân tích dữ liệu.
Thứ nhất, thống kê trung bình (Mean) giúp xác định xu hướng tập trung của dữ liệu, qua đó phản ánh đặc điểm chung hoặc mức độ đại diện của tập dữ liệu nghiên cứu. Đối với các thang đo thái độ, cảm nhận hoặc đánh giá, giá trị trung bình cho phép nhà nghiên cứu nhận diện khuynh hướng chung của đối tượng khảo sát theo các mức như tích cực – trung lập – tiêu cực. Đối với các thang đo số hoặc thang đo khoảng (ví dụ độ tuổi, số năm kinh nghiệm, thu nhập), giá trị trung bình phản ánh mức đại diện điển hình của mẫu nghiên cứu.
Thứ hai, chỉ số độ lệch chuẩn (Standard Deviation) được sử dụng để đánh giá mức độ phân tán của dữ liệu xung quanh giá trị trung bình. Độ lệch chuẩn càng nhỏ cho thấy dữ liệu càng tập trung, mức độ đồng thuận giữa các quan sát càng cao; ngược lại, độ lệch chuẩn lớn phản ánh sự khác biệt đáng kể giữa các đối tượng khảo sát, làm giảm khả năng đại diện của giá trị trung bình.
Thứ ba, thống kê mô tả đóng vai trò quan trọng trong làm sạch dữ liệu trước khi thực hiện các phân tích chuyên sâu. Việc kiểm soát giá trị nhỏ nhất (Minimum) và lớn nhất (Maximum) giúp phát hiện các lỗi nhập liệu, sai thang đo hoặc các giá trị ngoại lai cần được xử lý nhằm đảm bảo độ chính xác của kết quả phân tích.
2. Các tiêu chuẩn đánh giá kết quả thống kê trung bình
Tiêu chuẩn 1: Tính hợp lệ của dữ liệu (Minimum – Maximum)
Đây là bước kiểm tra bắt buộc nhằm phát hiện lỗi nhập liệu.
Nguyên tắc chung là giá trị nhỏ nhất và lớn nhất phải nằm trong đúng phạm vi thang đo đã thiết kế.
Ví dụ, nếu nghiên cứu sử dụng thang đo Likert từ 1 đến 5, kết quả hợp lệ khi Min = 1 và Max = 5. Trường hợp Min = 0 hoặc Max = 6, 7, 55… cho thấy dữ liệu bị lỗi và cần được kiểm tra, chỉnh sửa ngay trong bộ dữ liệu gốc. Nếu không xử lý, giá trị trung bình và các kết quả phân tích tiếp theo sẽ bị sai lệch nghiêm trọng.
Đối với thang đo số hoặc thang đo liên tục (ví dụ độ tuổi từ 1 đến 100), Min và Max phải nằm trong khoảng giá trị logic và phù hợp với đối tượng khảo sát. Các giá trị ngoài phạm vi này thường được xem là lỗi nhập liệu hoặc ngoại lai không hợp lý.
Tiêu chuẩn 2: Đánh giá giá trị trung bình (Mean) theo loại thang đo
Việc diễn giải giá trị trung bình cần phân biệt rõ giữa thang đo Likert và thang đo số (thang đo khoảng/liên tục).
2.1 Đối với thang đo Likert
Giá trị trung bình không được hiểu theo nghĩa số học thuần túy mà cần được diễn giải thông qua khoảng cách giá trị. Căn cứ vào số mức của thang đo (5 mức, 7 mức, 9 mức), các khoảng điểm được quy ước để xác định mức đánh giá từ rất thấp đến rất cao, phản ánh các trạng thái như tiêu cực – trung lập – tích cực, không hài lòng – hài lòng, không tin tưởng – tin tưởng, kém hiệu quả – hiệu quả. Cách tiếp cận này giúp chuẩn hóa việc diễn giải kết quả và đảm bảo tính nhất quán trong nghiên cứu khoa học.
Để đánh giá tổng quát mức độ phản ánh ý kiến thực tế của đối tượng khảo sát thông qua giá trị trung bình, nghiên cứu áp dụng phương pháp xác định khoảng cách giá trị nhằm phân loại mức độ đánh giá từ thấp đến cao.
Với thang đo Likert 5 mức độ, ý nghĩa các khoảng điểm được quy ước chuẩn như sau:
- Từ 1.00 – 1.80: Mức rất thấp (Rất tiêu cực/ Rất không hài lòng/ Rất không tin tưởng/ Rất không hiệu quả…)
- Từ 1.81 – 2.60: Mức thấp (Tiêu cực/ Không hài lòng/ Không tin tưởng/ Kém hiệu quả…)
- Từ 2.61 – 3.40: Mức trung bình (Trung lập/ Bình thường/ Không rõ ràng/ Đánh giá ở mức vừa phải…)
- Từ 3.41 – 4.20: Mức cao (Tích cực/ Hài lòng/ Tin tưởng/ Hiệu quả…)
- Từ 4.21 – 5.00: Mức rất cao (Rất tích cực/ Rất hài lòng/ Rất tin tưởng/ Rất hiệu quả…)
Với thang đo Likert 7 mức độ, ý nghĩa các khoảng điểm được quy ước chuẩn như sau:
- Từ 1.00 – 1.86: Mức rất thấp (Rất tiêu cực/ Rất không hài lòng/ Rất không tin tưởng/ Rất không hiệu quả…)
- Từ 1.87 – 2.71: Mức thấp (Tiêu cực/ Không hài lòng/ Không tin tưởng/ Kém hiệu quả…)
- Từ 2.72 – 3.57: Mức tương đối thấp (Hơi tiêu cực/ Hơi không hài lòng/ Ít tin tưởng/ Hiệu quả thấp…)
- Từ 3.58 – 4.43: Mức trung bình (Trung lập/ Bình thường/ Đánh giá ở mức vừa phải…)
- Từ 4.44 – 5.29: Mức tương đối cao (Khá tích cực/ Khá hài lòng/ Khá tin tưởng/ Khá hiệu quả…)
- Từ 5.30 – 6.14: Mức cao (Tích cực/ Hài lòng/ Tin tưởng/ Hiệu quả…)
- Từ 6.15 – 7.00: Mức rất cao (Rất tích cực/ Rất hài lòng/ Rất tin tưởng/ Rất hiệu quả…)
Với thang đo Likert 9 mức độ, ý nghĩa các khoảng điểm được quy ước chuẩn như sau:
- Từ 1.00 – 1.89: Mức rất rất thấp (Rất tiêu cực/ Rất không hài lòng/ Rất không tin tưởng/ Rất không hiệu quả…)
- Từ 1.90 – 2.78: Mức rất thấp (Tiêu cực rõ rệt/ Không hài lòng nhiều/ Ít tin tưởng/ Hiệu quả rất thấp…)
- Từ 2.79 – 3.67: Mức thấp (Tiêu cực/ Không hài lòng/ Không tin tưởng/ Hiệu quả thấp…)
- Từ 3.68 – 4.56: Mức tương đối thấp (Hơi tiêu cực/ Hơi không hài lòng/ Tin tưởng ở mức thấp/ Hiệu quả chưa cao…)
- Từ 4.57 – 5.44: Mức trung bình (Trung lập/ Bình thường/ Đánh giá ở mức vừa phải…)
- Từ 5.45 – 6.33: Mức tương đối cao (Khá tích cực/ Khá hài lòng/ Khá tin tưởng/ Khá hiệu quả…)
- Từ 6.34 – 7.22: Mức cao (Tích cực/ Hài lòng/ Tin tưởng/ Hiệu quả…)
- Từ 7.23 – 8.11: Mức rất cao (Rất tích cực/ Rất hài lòng/ Rất tin tưởng/ Rất hiệu quả…)
- Từ 8.12 – 9.00: Mức cực kỳ cao (Cực kỳ tích cực/ Cực kỳ hài lòng/ Cực kỳ tin tưởng/ Cực kỳ hiệu quả…)
2.2 Đối với thang đo số hoặc thang đo khoảng liên tục
Đối với các biến được đo lường bằng thang đo số hoặc thang đo khoảng liên tục như độ tuổi, số nhân khẩu trong hộ gia đình hay thu nhập thực tế, giá trị trung bình (Mean) được diễn giải trực tiếp theo ý nghĩa số học, không cần quy đổi sang các mức cao – thấp như đối với thang đo Likert.
| Cách đo lường | Đặc điểm dữ liệu | Ví dụ | Phương pháp thống kê phù hợp | Ý nghĩa khi phân tích |
|---|---|---|---|---|
| Biến phân loại | Giá trị được chia thành các nhóm hoặc mốc | Độ tuổi: dưới 25, 25–35, trên 35 Thu nhập: dưới 5 triệu, 5–10 triệu, trên 10 triệu |
Thống kê tần số và tỷ lệ phần trăm (%) | Mô tả cơ cấu mẫu và phân bố đối tượng nghiên cứu |
| Biến định lượng liên tục | Giá trị cụ thể, liên tục theo đơn vị đo | Độ tuổi: 27, 28, 29, 30,…, 42 Thu nhập: 8.5 triệu; 12.3 triệu |
Giá trị trung bình (Mean), độ lệch chuẩn (Std. Deviation) | Giúp đánh giá mức độ trung bình và độ phân tán của dữ liệu |
Trong các trường hợp trên, giá trị trung bình đóng vai trò là chỉ số đại diện trực tiếp cho đặc điểm của mẫu nghiên cứu, còn độ lệch chuẩn giúp đánh giá mức độ phân tán và tính đồng nhất của dữ liệu.
Như vậy, đối với thang đo số hoặc thang đo khoảng liên tục, nhà nghiên cứu không áp dụng phương pháp phân loại theo khoảng chuẩn như thang đo Likert, mà tập trung diễn giải giá trị trung bình gắn với bối cảnh thực tiễn và đặc điểm của mẫu khảo sát. Cách tiếp cận này giúp kết quả phân tích vừa chính xác về mặt thống kê, vừa mang giá trị ứng dụng cao trong nghiên cứu định lượng và thực hành phân tích dữ liệu trên SPSS.
Tiêu chuẩn 3: Mức độ đồng thuận của dữ liệu (Độ lệch chuẩn – Standard Deviation)
Độ lệch chuẩn phản ánh mức độ thống nhất trong câu trả lời của các đối tượng khảo sát.
Khi độ lệch chuẩn nhỏ (thường nhỏ hơn 1 đối với thang đo Likert), dữ liệu được xem là tập trung, cho thấy mức độ đồng thuận cao và giá trị trung bình có độ tin cậy tốt. Ngược lại, độ lệch chuẩn lớn cho thấy dữ liệu phân tán mạnh, phản ánh sự khác biệt đáng kể trong quan điểm hoặc đặc điểm của các đối tượng khảo sát, từ đó làm giảm khả năng đại diện của giá trị trung bình.
3. Quy trình thực hiện trên phần mềm SPSS 27
Để các bạn dễ hình dung và nắm bắt cách đọc kết quả sát với thực tế, trong hướng dẫn này mình sẽ sử dụng bộ dữ liệu mẫu từ đề tài "Chất lượng dịch vụ Internet Banking tại Ngân hàng MBBank".
Từ giao diện làm việc của SPSS, các bạn vào: Analyze > Descriptive Statistics > Descriptives…

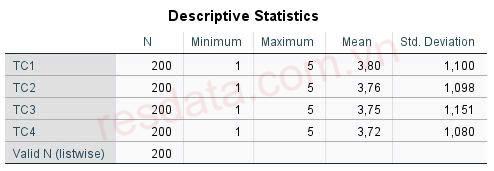
Tại cửa sổ Descriptives, đưa các biến cần thống kê trung bình vào mục Variable(s), có thể đưa cùng lúc nhiều biến vào thực hiện thống kê. Trong hướng dẫn này, mình sẽ thực hành mẫu với nhóm biến Tin cậy (từ TC1 đến TC4) nên mình sẽ đưa các biến này vào mục Variable(s).

Bên phải có các mục Options, Style và Bootstrap để chúng ta lựa chọn loại thống kê trung bình cũng như định dạng kết quả xuất ra. Tuy nhiên, thường chúng ta chỉ sử dụng đến mục Options. Trong Options, có các loại thống kê để chúng ta lựa chọn tùy theo mục đích đánh giá, SPSS thiết lập mặc định các mục trong phần này gồm:
- Mean: giá trị trung bình
- Std. deviation: độ lệch chuẩn.
- Minimum: giá trị nhỏ nhất
- Maximum: giá trị lớn nhất
Nhấp chuột vào Continue để quay lại cửa sổ ban đầu, nhấp vào OK để xuất kết quả ra output.
Chúng ta sẽ đọc kết quả ở bảng Descriptive Statistics. N là cột cần quan tâm trước nhất để xem có dữ liệu giá trị khuyết Missing hay không, nếu có Missing Value thì giá trị N này sẽ khác với cỡ mẫu. Tiếp tục nhìn vào kết quả giá trị nhỏ nhất, lớn nhất để xem có tình trạng giá trị vượt ngoài giới hạn thang đo hay không. Hai giá trị còn lại là trung bình và độ lệch chuẩn thường sẽ đi theo kết quả của giá trị nhỏ nhất, lớn nhất. Nếu có tình trạng giá trị vượt ngoài thang điểm đánh giá, giá trị trung bình và độ lệch chuẩn sẽ có sự đột biến.


Kết quả thống kê mô tả cho thấy giá trị trung bình (Mean) của các biến từ TC1 đến TC4 đều dao động trong khoảng 3.72 đến 3.80. Theo quy tắc làm tròn, các giá trị này đều xấp xỉ mức 4 trên thang đo Likert 5 điểm.
Điều này phản ánh rằng khách hàng tham gia khảo sát có xu hướng đồng ý với các tiêu chí về sự Tin cậy của dịch vụ Internet Banking tại MBBank. Cụ thể, khách hàng đánh giá cao việc ngân hàng luôn thực hiện đúng cam kết, đảm bảo giao dịch chính xác, an toàn bảo mật và luôn đặt quyền lợi khách hàng lên hàng đầu.
Nhìn chung, kết quả này là một tín hiệu tích cực, cho thấy MBBank đã xây dựng được uy tín tốt trong tâm trí khách hàng thông qua chất lượng phục vụ ổn định và đáng tin cậy.
Trên đây là bài viết hướng dẫn chi tiết về thống kê mô tả trong SPSS, tập trung vào cách tính toán và diễn giải giá trị trung bình (Mean), độ lệch chuẩn (Standard Deviation – Std.), giá trị nhỏ nhất (Minimum) và lớn nhất (Maximum) cho các biến định lượng và thang đo Likert. Thông qua việc phân biệt rõ giữa thang đo Likert và thang đo số/ thang đo khoảng liên tục, bài viết giúp người học hiểu đúng bản chất dữ liệu, tránh sai lầm khi diễn giải kết quả thống kê. Hy vọng nội dung này sẽ hỗ trợ bạn đọc nắm vững cách đọc kết quả thống kê mô tả trên SPSS, từ đó áp dụng hiệu quả trong các nghiên cứu định lượng, khóa luận, luận văn và đề tài khoa học thực nghiệm.
Để hạn chế sai sót trong quá trình xử lý dữ liệu và đảm bảo kết quả phân tích phản ánh đúng bản chất nghiên cứu, bạn nên tham khảo thêm bài viết tổng hợp những điều cần lưu ý khi chạy SPSS cho kết quả tốt , trong đó trình bày toàn diện các vấn đề quan trọng từ chuẩn bị dữ liệu, kiểm định thang đo đến phân tích và diễn giải kết quả.
------------------------
Resdata hỗ trợ bạn những gì?
✅ Tư vấn & định hướng toàn bộ quy trình xử lý dữ liệu SPSS: Rà soát thang đo, phát hiện và xử lý các biến không phù hợp, đồng thời định hướng từng bước phân tích (Cronbach’s Alpha, EFA, hồi quy/SEM…) theo đúng bản chất dữ liệu, bối cảnh nghiên cứu và mục tiêu đề tài, giúp kết quả phản ánh thực tế nghiên cứu và đáp ứng yêu cầu học thuật.
✅ Hỗ trợ SPSS 1 kèm 1 qua ultraview: Hướng dẫn chi tiết từng bước thực hành và cách viết nhận xét chuẩn học thuật.
✅ Xử lý nhanh – đúng chuẩn: Xử lý kết quả trong ngày. Phù hợp cho khóa luận, luận văn, luận án và bài báo khoa học.
✅ Cam kết chỉnh sửa theo góp ý của giảng viên/hội đồng cho đến khi đạt yêu cầu.
Nếu bạn đang gặp phải các tình huống trên và chưa tìm được hướng xử lý phù hợp, đừng ngần ngại liên hệ ngay: Hotline: 0907 786 895.
Resdata luôn sẵn sàng đồng hành cùng bạn với phương châm: Nhanh chóng – Tin cậy – Bảo mật – Chi phí hợp lý.






